

Better Billing Launched to All Nextpoint Users
The evolution continues. Here are the latest enhancements to your ediscovery and case management software.
This spring, we’re announcing the official launch of a highly anticipated feature, along with a few quick wins and an exciting preview of what’s to come.
Simplify Billing with the Nextpoint Invoice Generator – Now Available to All Users
Following a successful beta release, the Subscription Pass-Through Invoice Generator is now officially available to all Nextpoint users.
Nextpoint revolutionized ediscovery pricing with our per-user, unlimited data model – and now, we’re making it even easier for legal teams to maximize their profitability and control costs with seamless, automated invoicing.
With the new Subscription Pass-Through Invoice Generator, you can:
- Easily calculate monthly billing for each case
- Generate fully customizable invoices for your clients
- Efficiently allocate and pass on software costs with minimal effort
Built to simplify cost allocation and free up your team to focus on winning cases, this tool empowers legal professionals to maximize profits without the hassle of manual invoicing.

Quick Wins and Efficiency Gains
Streamlined Objection Visibility: A new pop-up tab allows you to view objection types instantly alongside designations, saving you time and keeping your focus in one place.
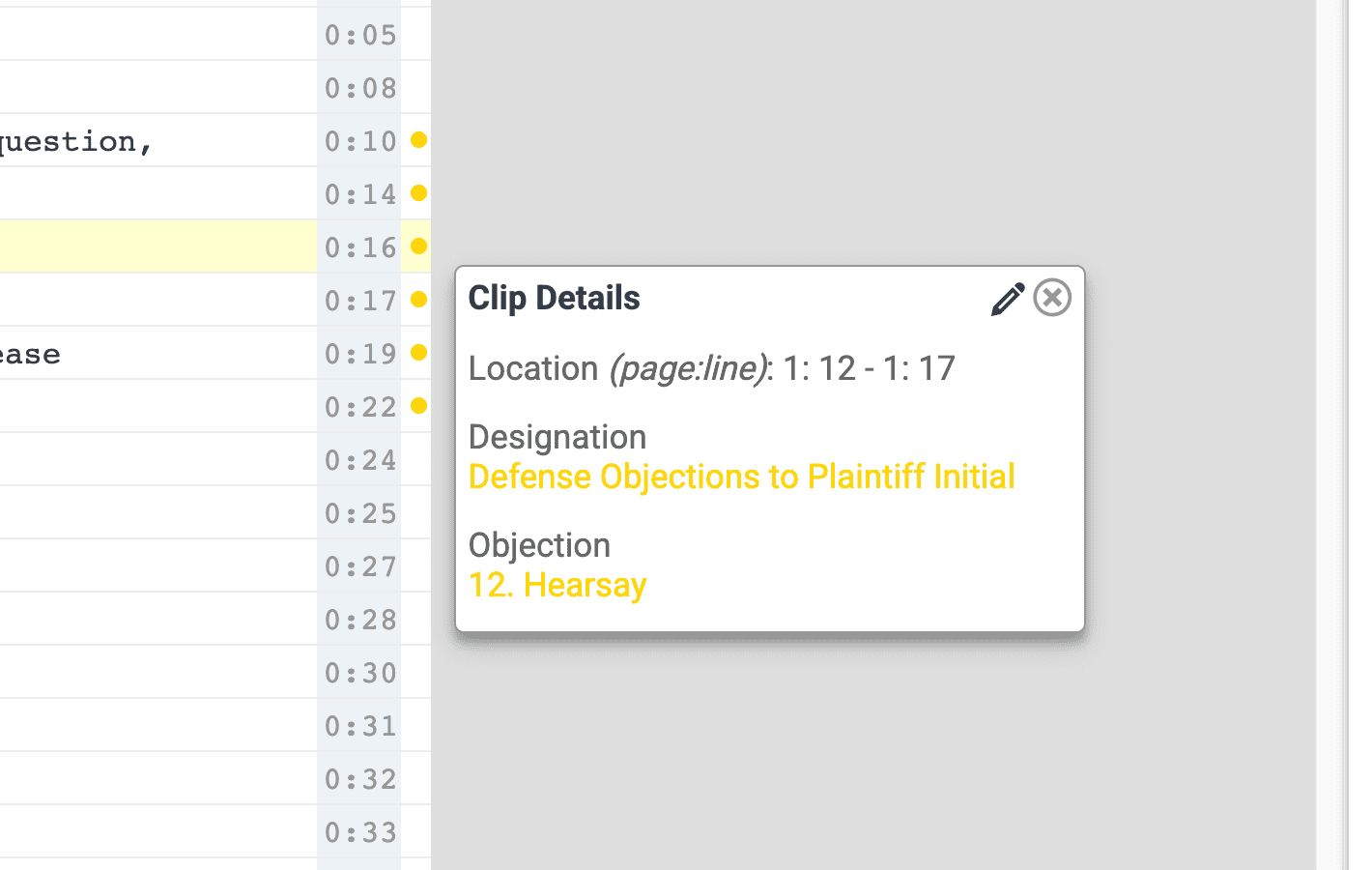
Exhibit Stamping, Your Way: Exhibit stamps now automatically adopt folder colors, giving you more control, consistency, and flexibility in your trial prep.


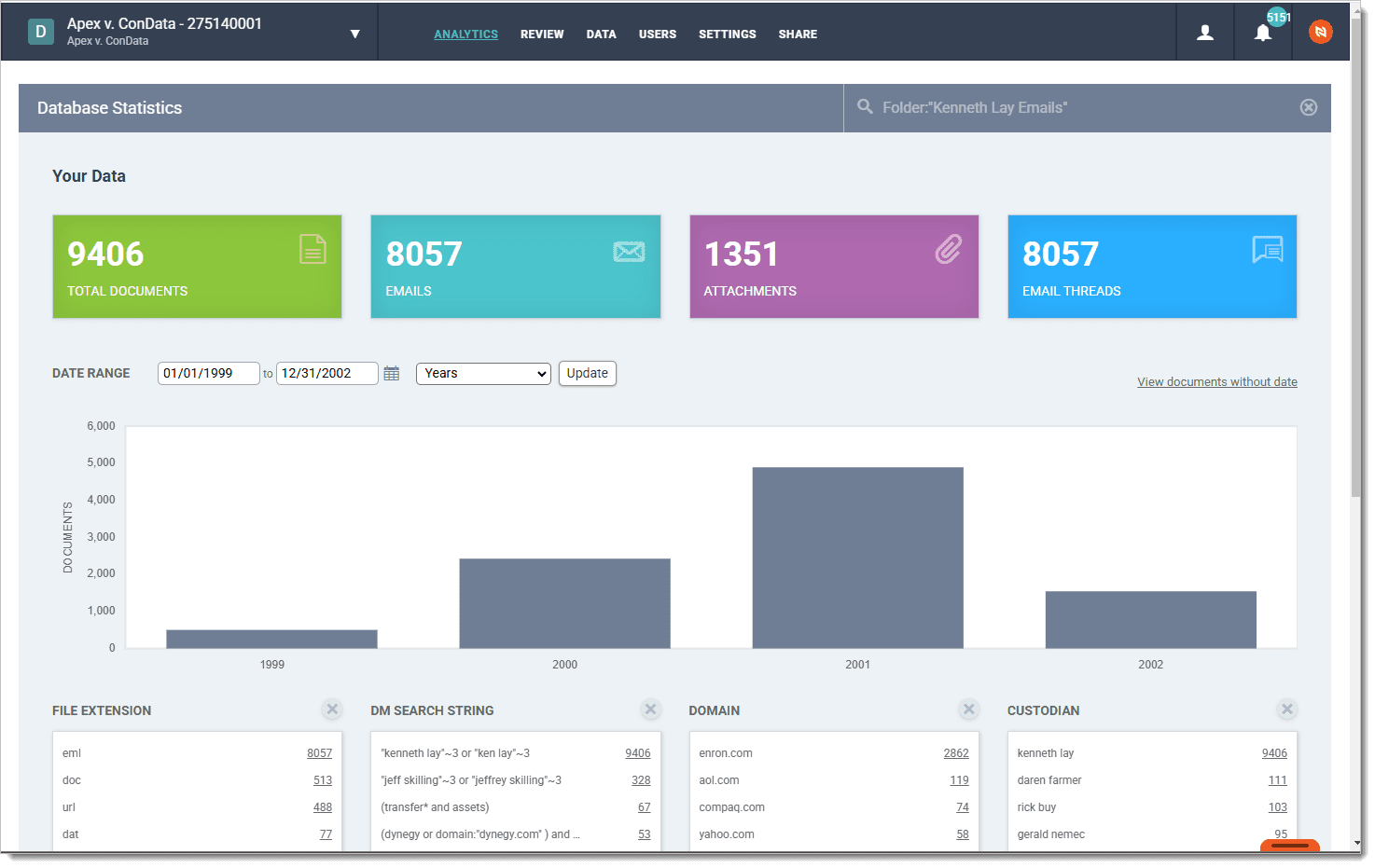
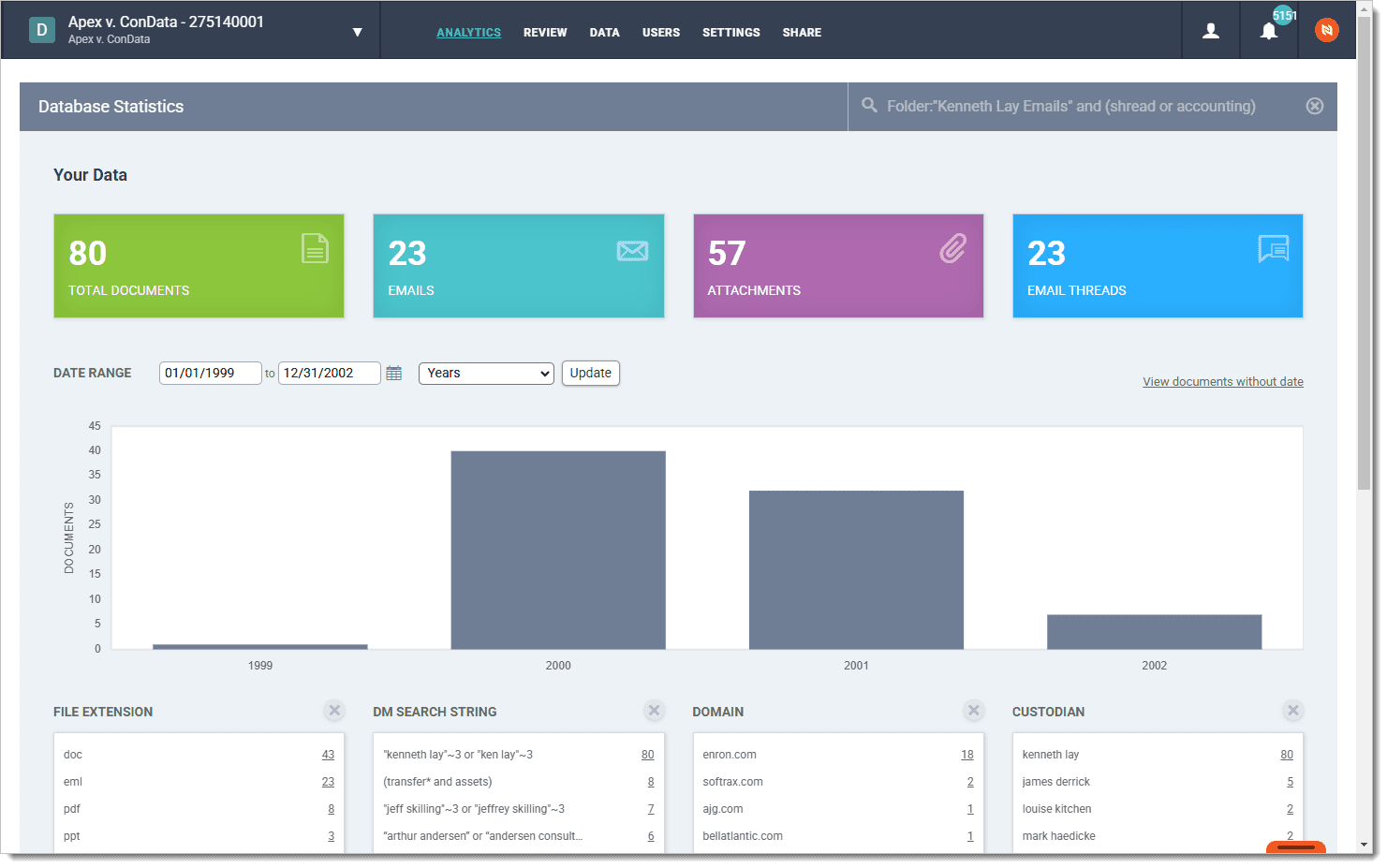
Enhanced Searching in Analytics: You’ll now be able to edit and build on searches in the Analytics dashboard, making it easier to refine your results and dive deeper into your data.


Coming Soon: AI-Powered Transcript Summaries
We’re excited to announce an AI-powered feature that will be a game-changer for your transcript analysis: Automated summaries that recap even the densest transcripts in seconds. This innovative tool utilizes generative AI to produce narrative, chronological, and table of contents summaries for deposition transcripts, transforming the way you use Nextpoint to manage your depositions and proceedings.
Keep an eye out for more information on the release of AI-powered transcript summaries, slated for this summer.
Questions? Feedback? Please contact our team at support@nextpoint.com.
Maximize Profitability and Efficiency with New Nextpoint Features
The evolution continues. Here are the latest enhancements to your ediscovery and case management software.
As Nextpoint wraps up the year, we’re announcing exciting new features that will help our users maximize profitability and efficiency. See below for a preview of what’s included.
Nextpoint Invoice Generator Simplifies Billing and Maximizes Profits
Nextpoint was the first ediscovery company to launch a per-user pricing model with unlimited data, providing a much-needed alternative to the per-GB costs that dominated the industry. Our users have enjoyed the predictability and affordability of Nextpoint pricing ever since. As legal data volumes see exponential growth, the Nextpoint approach to ediscovery pricing is more important than ever.
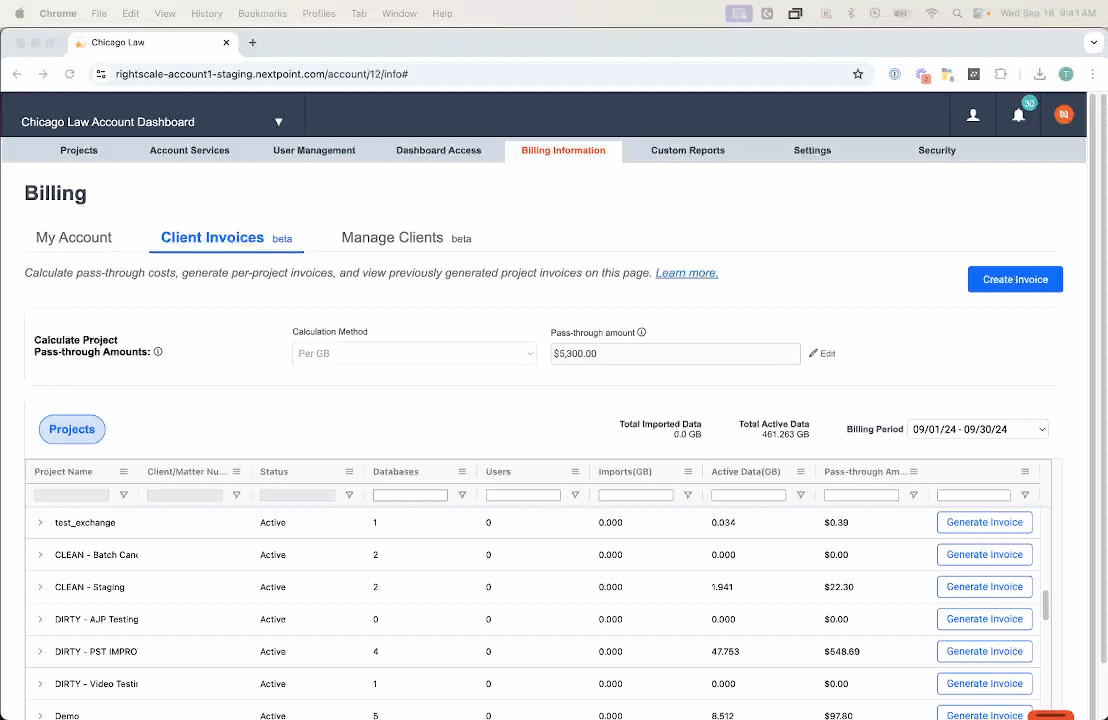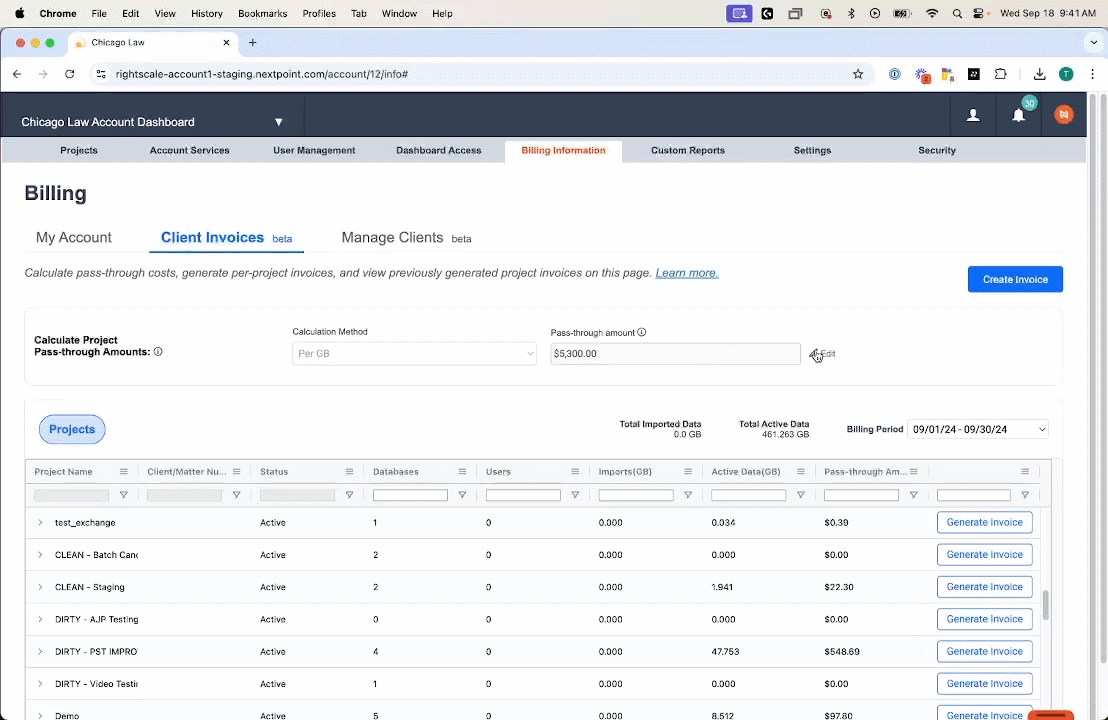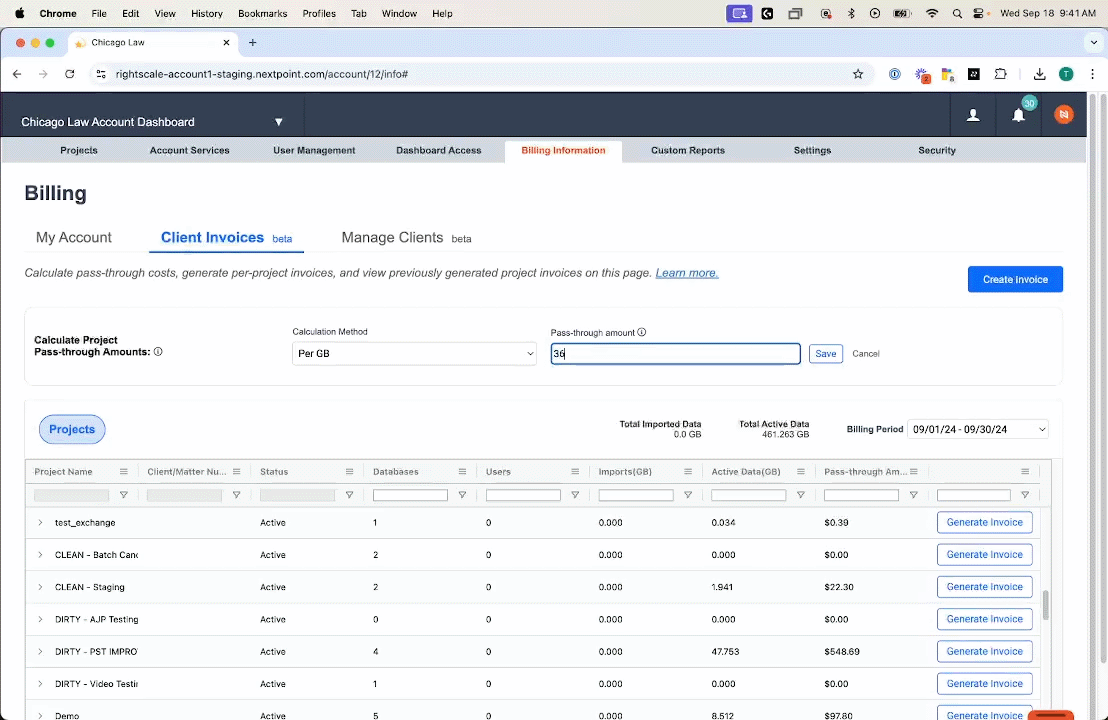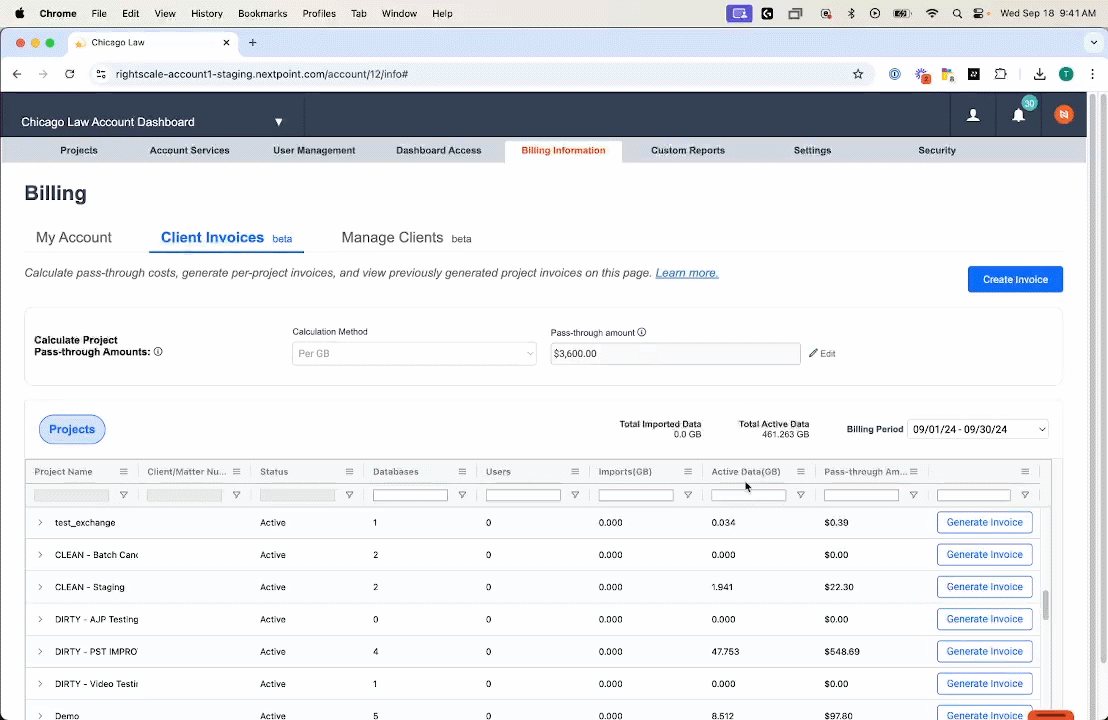
No matter what pricing structure is in place, legal teams can reduce their ediscovery expenses by passing through software costs to their clients. Nextpoint is launching a new tool that will make simplify and streamline this process: a Subscription Pass-Through Invoice Generator. Now, users can take advantage of our predictable pricing along with a seamless method to pass these costs through to their clients.
Currently available as a beta release, the tool will calculate how much should be invoiced for each case in a given month and generate a fully customizable invoice to share with the appropriate party. By simplifying the pass-through process, Nextpoint ensures that legal teams can focus on what they do best – delivering exceptional legal services – while we handle the complexities of cost allocation and invoicing.
Meet Ned: The Nextpoint AI Support Assistant
At Nextpoint, we take pride in our user-friendly interface and the wealth of onboarding and training materials available to our clients. Still, we understand that the ediscovery process is complex, and questions will inevitably arise as you navigate those complexities. We created a companion that will supply streamlined answers to your questions in an instant, empowering you to execute ediscovery projects without disruption.
We’re excited to introduce Ned, the Nextpoint AI Support Assistant, a smart helper built to deliver faster, more personalized support at your fingertips. Get instant, relevant answers from our help center, effortless navigation with direct links, and intelligent topic recommendations.
And if you need further assistance, our human support team is still just a click away. They’ll have access to your chat history with Ned, so they can quickly understand your challenges and provide the right solutions. We know our users love the accessible, hands-on support our team provides, and we’re excited to utilize AI to enhance our offerings.
Who Is Ned?
Ned, short for Nextpoint eDiscovery, is the friendly, knowledgeable, and highly efficient AI Support Assistant designed to guide Nextpoint users through our comprehensive litigation software. Whether you’re a legal professional, paralegal, or IT administrator, Ned is always available to answer questions, troubleshoot issues, and provide personalized solutions to help you get the most out of the Nextpoint platform.

Efficiency Gains from Collection to Case Building
This quarter, we launched several updates to enhance user efficiency in Nextpoint. Whether we’re addressing small challenges or major feature needs, we always listen to our users as we make improvements to ensure Nextpoint is a valuable part of your litigation process.
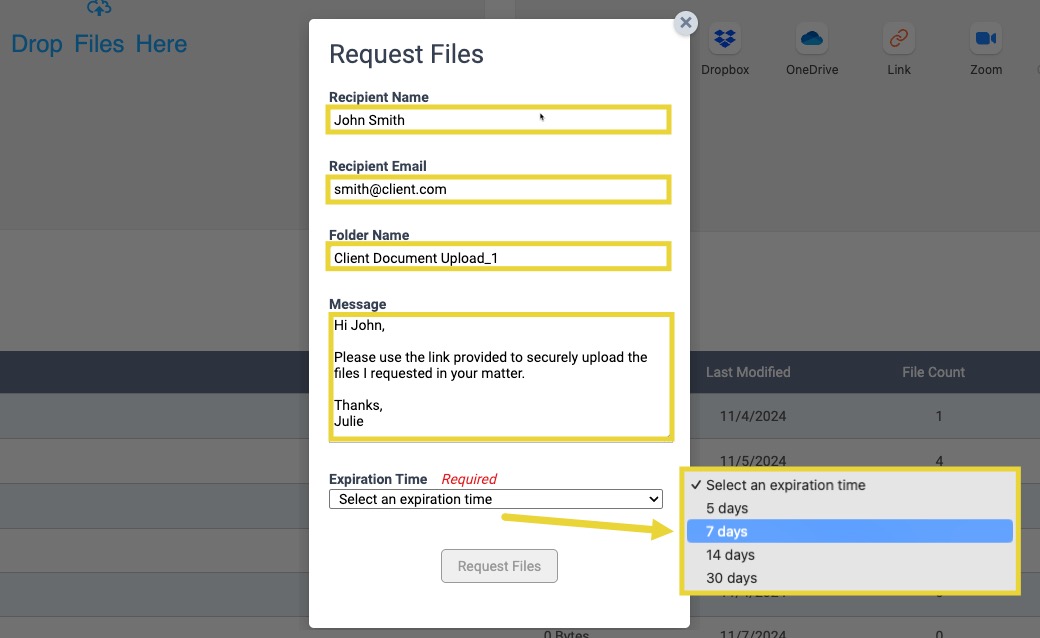
Custom Expiration Dates for File Requests
In any Nextpoint database, you can securely Request Files from any third party (clients, counsel, etc.) from your database File Room. The recipient of that request will receive a secure link to upload their respective files, and you can access the uploaded files right away.
Now, this feature offers greater flexibility, allowing Nextpoint users to set a custom expiration window for the secure link to upload files. They can choose between 5, 7, 14, and 30 days. This update reduces the need for repeated requests and provides better control over managing expiration timelines.
File Room Extraction Enhancements
In the Nextpoint File Room, users can unzip and extract data from zipped or compressed files. In this upgrade, we expanded the size of compressed files that can be uploaded and extracted in Nextpoint, accommodating the rapid growth of typical legal data volumes. We also now support more archive formats in addition to ZIP files, including .7z, .rar, and .tar. These changes, along with a clearer interface for streamlined workflows, will reduce friction, save time, and simplify handling large data sets.
Grid View Updates for Smoother Review
When you’re progressing through an enormous document review, it can be easy to lose your place amid a sea of muddled files and similar documents. Now, the last document you examined in the Document Viewer will be highlighted in Grid View, empowering you to navigate between documents quickly and efficiently.
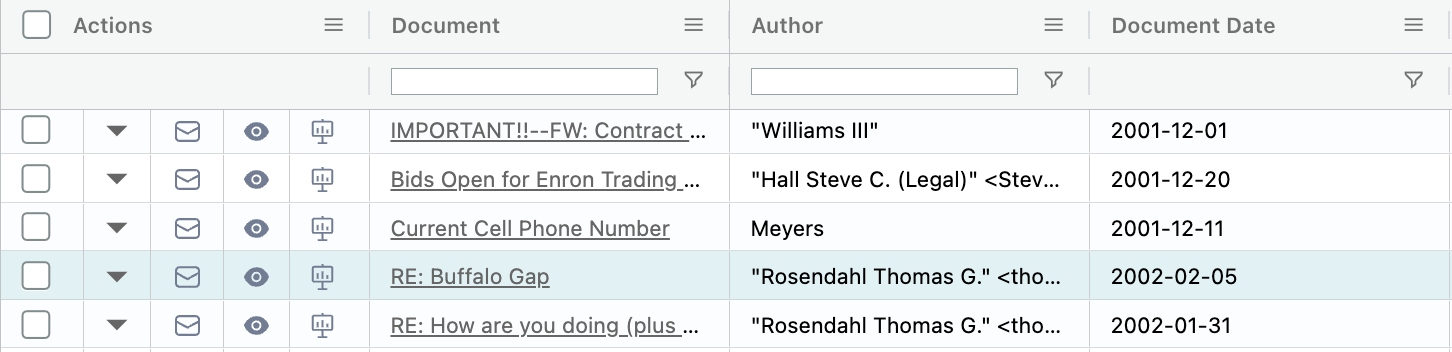
Reordering Documents in a Folder
You may sometimes need to change the order of documents within a folder after it has already been set up. This can be helpful when exporting items like privilege logs and exhibit lists. An update to Document Reordering brings greater clarity, functionality, and ease of use to the feature. Key changes include enhanced tooltips, the removal of automatic document family inclusion, and a new “Choose Order” feature that allows sorting folders by date, family, or specific fields.
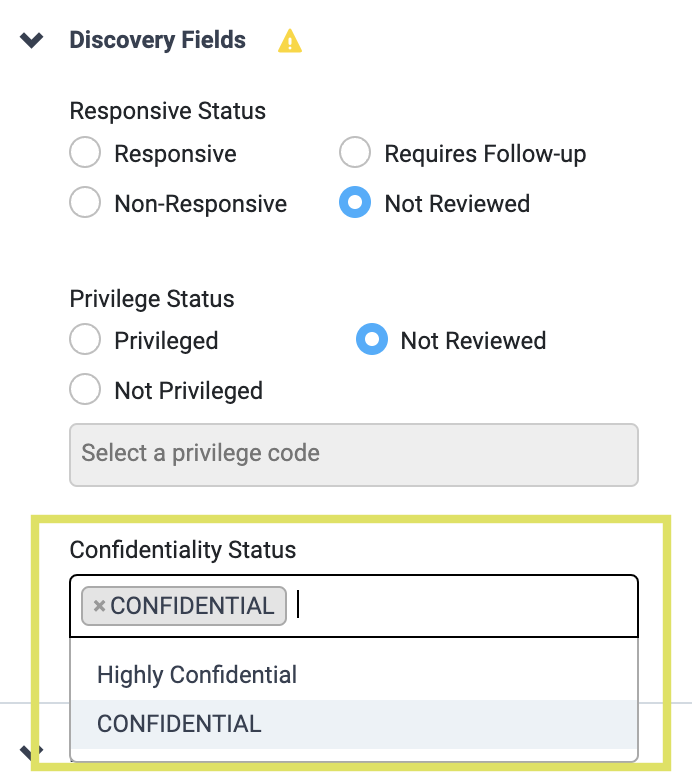
Confidentiality Stamping in Litigation
Nextpoint users now have a seamless way to add, remove, and modify Confidentiality Stamps on document pages in the Litigation suite, a valuable feature that was previously only available in Discovery databases. You’ll find the ability to create confidentiality codes in your document settings, manage document status in hot fields, and select a stamp placement in your endorsement templates. New information and needs can arise at any point across the litigation lifecycle, and we’re excited to provide our users with a more unified experience at every stage of their case.
Quick Wins and Enhancements
These are all the bug fixes and quick wins our software team has been working on this quarter to make sure Nextpoint provides the smoothest experience possible for our users.
Preservation & Processing Enhancements
- Enhanced handling of HTML characters in uploads ensures seamless processing.
- Load file text/native paths for load file imports are now generated automatically based on File Room naming conventions of the user selection for greater accuracy.
- Simplified load file imports leveraging image_file by removing the unnecessary Skipper column requirement.
- Time field mapping has been standardized to ensure accurate master date-time values.
- When a file is unzipped, it includes the file path in the metadata; and combines any sub-folder path in the zip in the file name.
Review & Analysis Enhancements
- Page numbers now display consistently in the document viewer for a smoother reading experience.
- Custom page start numbers for proceedings can now be set, offering more flexibility for users.
- Document issues can now be created from Documents > Issues without triggering page errors.
- Performance has been optimized when loading more than 250 related documents, and navigating email chains is now more efficient.
- Responsiveness, privilege, and confidentiality settings can now be added back to grid view templates after removal.
- The file path grid view filter now stays intact when pressing enter, improving workflow consistency.
Production & Presentation Enhancements
- Endorsement email copy has been improved for clearer and more consistent messaging.
- Export templates now feature clearer language, with optimized PDF image export defaults for common workflows.
- Non-advanced users no longer see the Exchange option in grid view, eliminating the 404 error.
- Exchange defaults for transferring natives and native placeholders have been optimized for better efficiency.
- Users can now easily toggle between treatments and the original page view in the theater for improved navigation.
Questions? Feedback? Please contact our team at support@nextpoint.com.
Triumph in the Era of Big Data: On Point 2024 Product Announcements
The evolution continues. Here are the latest enhancements to your ediscovery and case management software.
At On Point 2024, we announced exciting new features that will help our users triumph in the era of big data. See below for a preview of what’s included.
Nextpoint Invoice Generator Simplifies Billing and Maximizes Profits
Nextpoint was the first ediscovery company to launch a per-user pricing model with unlimited data, providing a much-needed alternative to the per-GB costs that dominated the industry. Our users have enjoyed the predictability and affordability of Nextpoint pricing ever since. As legal data volumes see exponential growth, the Nextpoint approach to ediscovery pricing is more important than ever.
No matter what pricing structure is in place, legal teams can reduce their ediscovery expenses by passing through software costs to their clients. Nextpoint is launching a new tool that will make simplify and streamline this process: a Subscription Pass-Through Invoice Generator. Now, users can take advantage of our predictable pricing along with a seamless method to pass these costs through to their clients.
The tool will calculate how much should be invoiced for each case in a given month and generate a fully customizable invoice to share with the appropriate party. By simplifying the pass-through process, Nextpoint ensures that legal teams can focus on what they do best – delivering exceptional legal services – while we handle the complexities of cost allocation and invoicing.
Nextpoint AI Streamlines Support for Users
At Nextpoint, we take pride in our user-friendly interface and the wealth of onboarding and training materials available to our clients. Still, we understand that the ediscovery process is complex, and questions will inevitably arise as you navigate those complexities. We created a companion that will supply streamlined answers to your questions in an instant, empowering you to execute ediscovery projects without disruption.
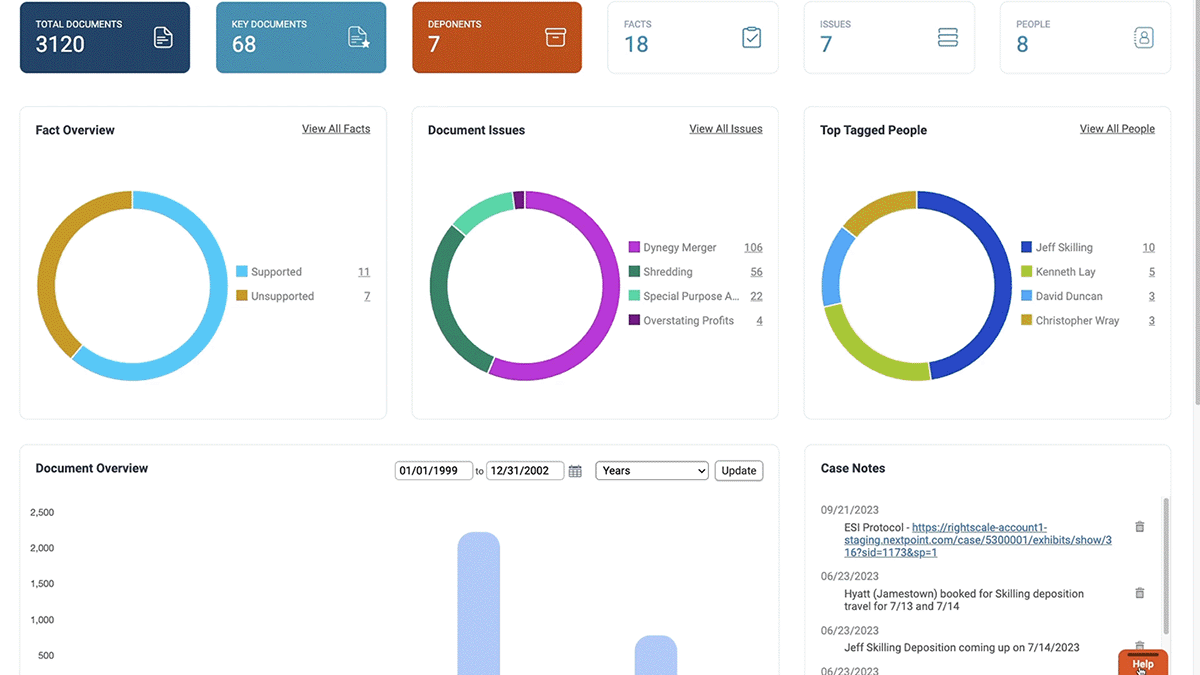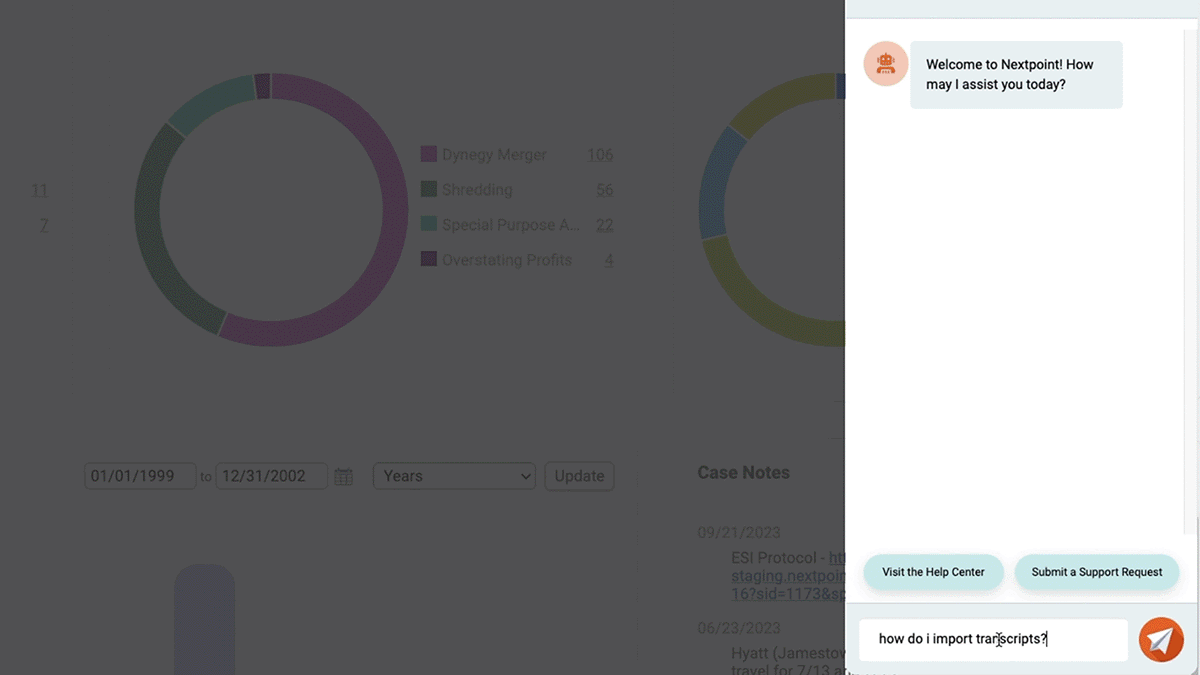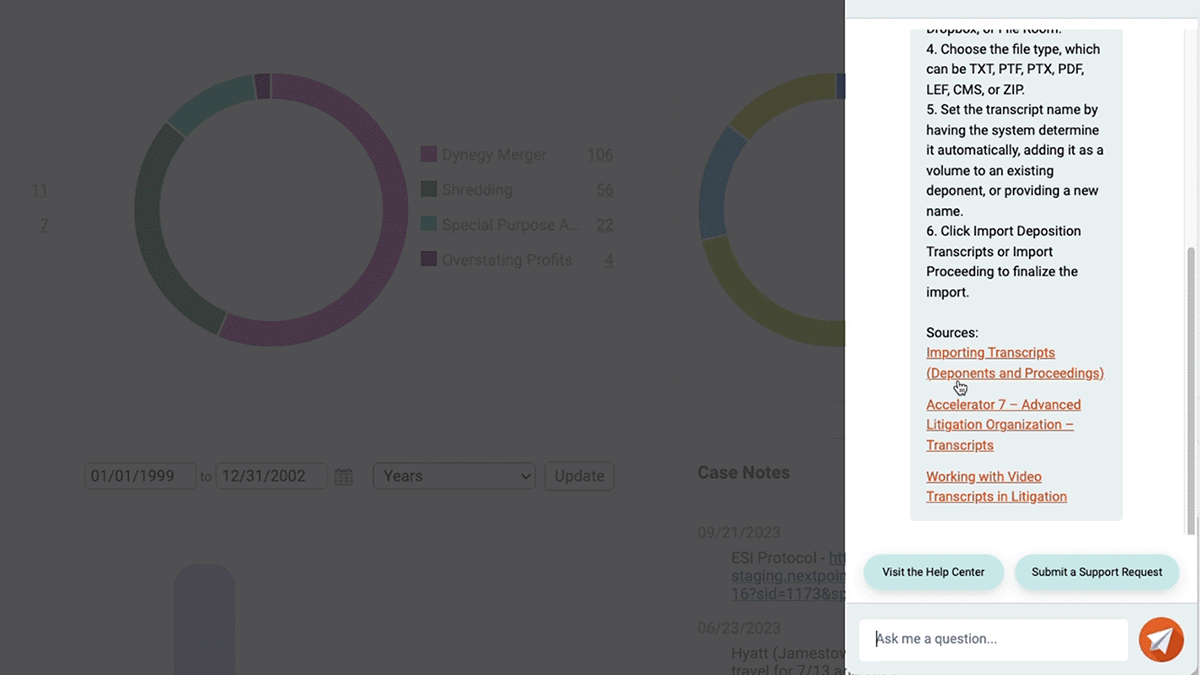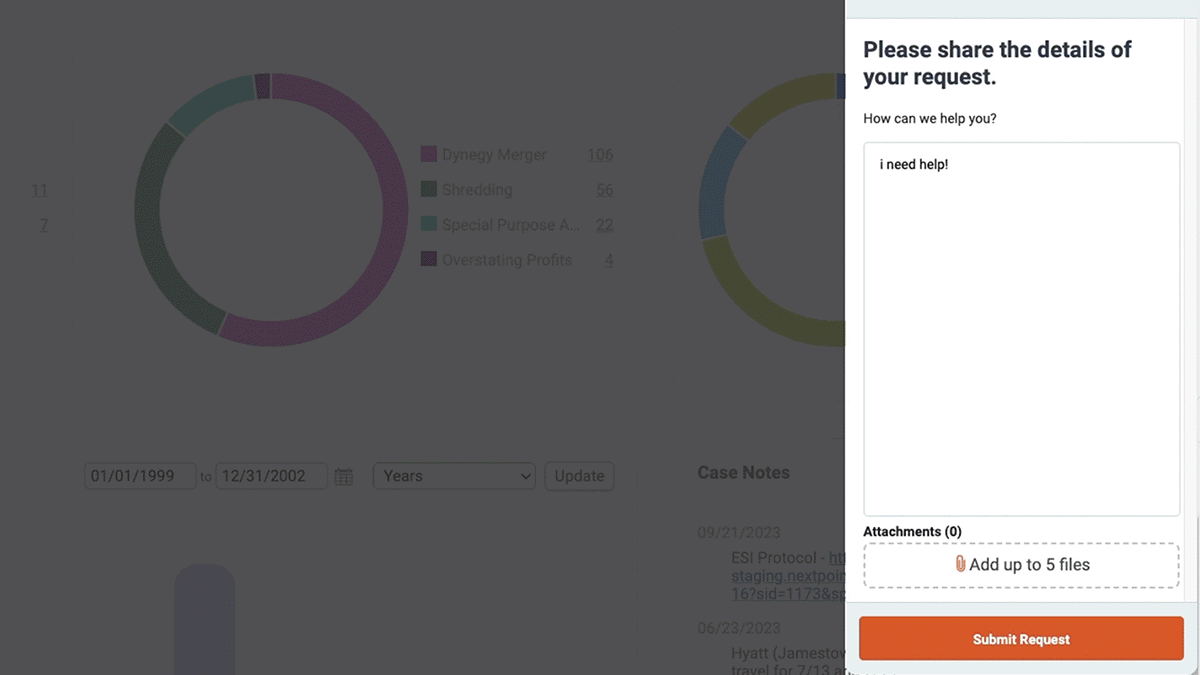
We’re excited to introduce the Nextpoint AI Support Assistant, a smart helper built to deliver faster, more personalized support at your fingertips. Get instant, relevant answers from our help center, effortless navigation with direct links, and intelligent topic recommendations.
And if you need further assistance, our human support team is still just a click away. They’ll have access to your chat history with the AI Support Assistant, so they can quickly understand your challenges and provide the right solutions. We know our users love the accessible, hands-on support our team provides, and we’re excited to utilize AI to enhance our offerings.
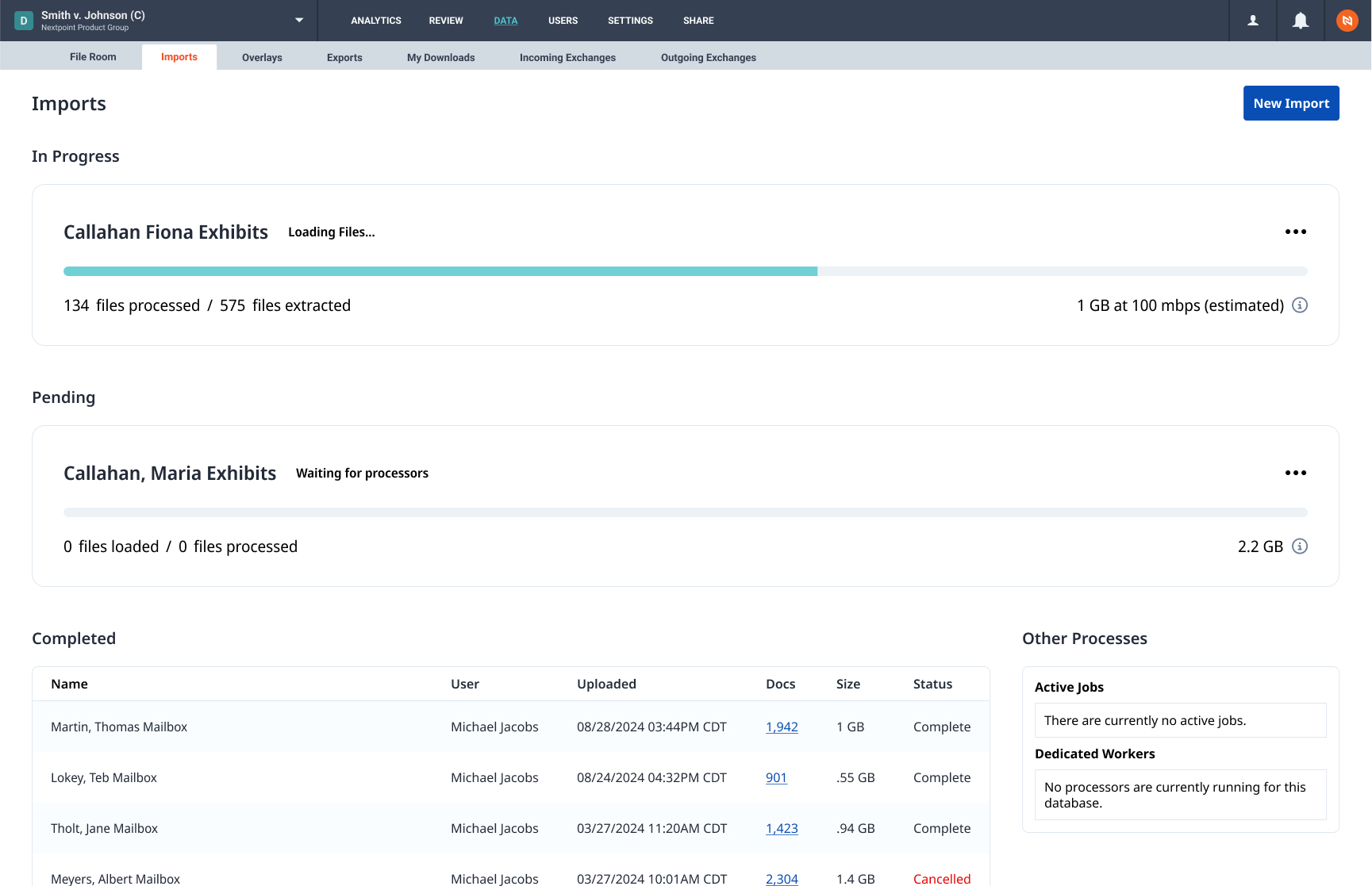
Introducing the Next Generation of Data Processing
In the early development of Nextpoint software, we built a proprietary processing engine that has enabled us to host and manage data for thousands of clients at a reasonable price, all while providing the tools you need to execute ediscovery smoothly. Since then, legal data volumes have exploded, and ESI has reached heightened complexity. Now, we’re revamping our processing engine to meet the needs of our modern, data-centric world.
“NextGen Processing,” coming in 2025, will set the foundation for the future of eLaw and give us the tools to meet any need that arises for our users. Your processing jobs will be faster and smoother, and you’ll have a new Import Status Monitor that provides up-to-date progress indicators, real-time tracking, and estimated completion times. The redesigned Batch Details Page will offer clear, actionable guidance, helping users quickly navigate issues and confirm all data is accounted for.
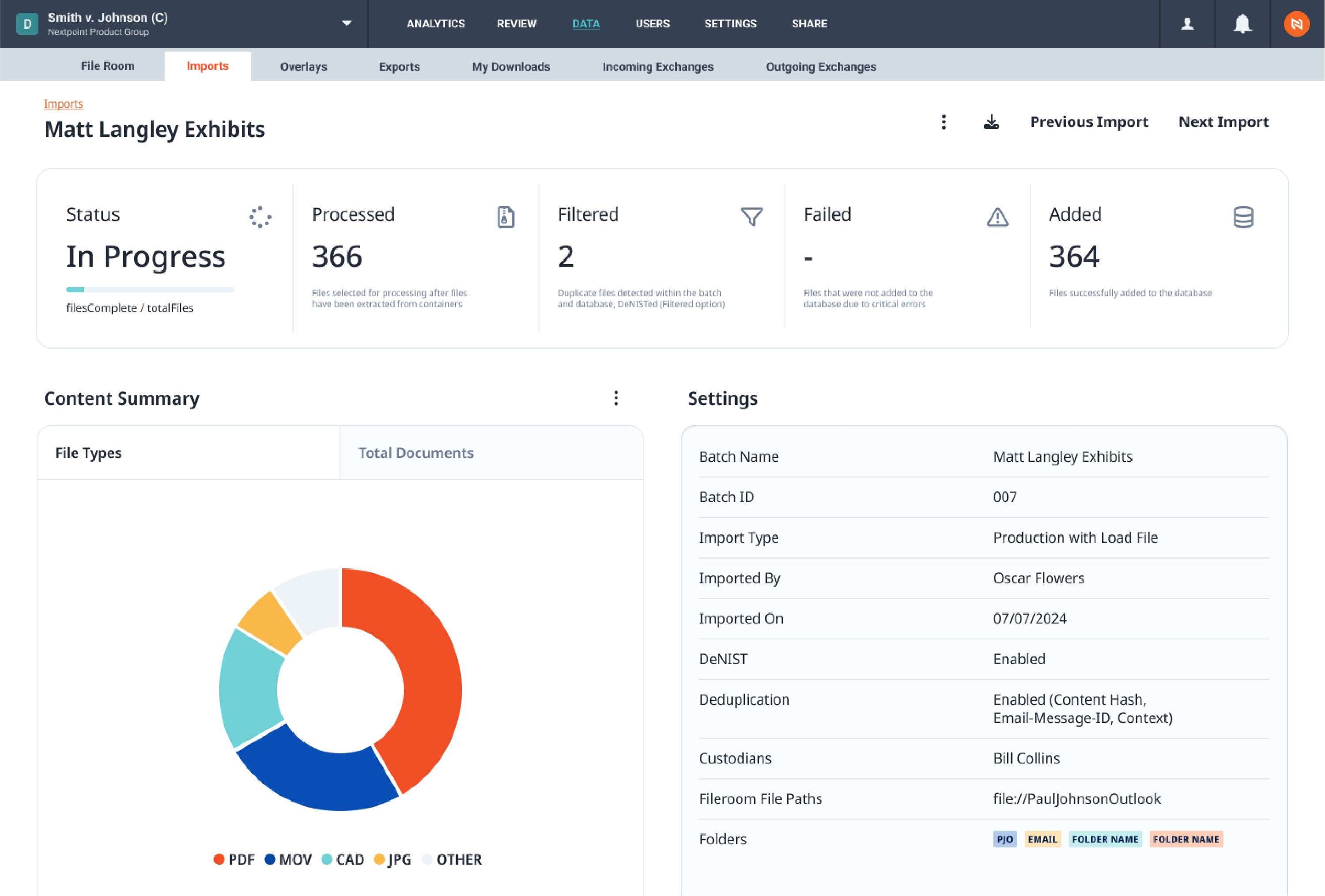
The new generation of Nextpoint will also feature an enhanced document viewer and annotation experience. Analyzing documents and adding notes and redactions will be more seamless than ever. As we head into the digital future of litigation, Nextpoint will have the infrastructure to continue providing innovative, reliable software to support you and your team throughout the legal process.
Preview the New Nextpoint Look
A stronger foundation for data processing is only one component of the next generation of eLaw. Nextpoint will also have a totally new look and feel in 2025, thanks to the implementation of our new design system.
This design system will enable us to deliver a more modern, efficient, and consistent interface to our users. It will also make Nextpoint software more adaptable and scalable as we evolve to meet the changing needs of modern litigation.
Watch the On Point 2024 Product Spotlight
Get a closer look at the latest Nextpoint updates in our product spotlight, presented at On Point 2024. Members of our product team and Nextpoint Law Group came together to share how these new features will streamline your workflows as we head into the future of eLaw.
Questions? Feedback? Please contact our team at support@nextpoint.com.
Advanced Security and Privacy for Modern Litigation
The evolution continues. Here are the latest enhancements to your ediscovery and case management software.
This week, we launched new features that enhanced data security for the modern litigation landscape. See below for a preview of what’s included.
Simplify Security with Single Sign-On
At Nextpoint, we understand that managing multiple login credentials across platforms slows down your team and introduces security risks. Our new Single Sign-On (SSO) solution addresses the issues caused by this password fatigue by enabling a single login for Nextpoint and other platforms, enhancing security and simplifying daily operations. With Nextpoint’s SSO, you’re adopting a more secure, compliant, and efficient practice that empowers collaboration without sacrificing integrity.
SSO also gives you the power to set security standards to meet the unique needs of your team. Your IT admin can easily manage user access for all your firm’s technology platforms in one space. All you need is an identity provider (IdP) like Azure or Okta, which can be seamlessly integrated with Nextpoint. Click here to learn more about Nextpoint security and SSO.
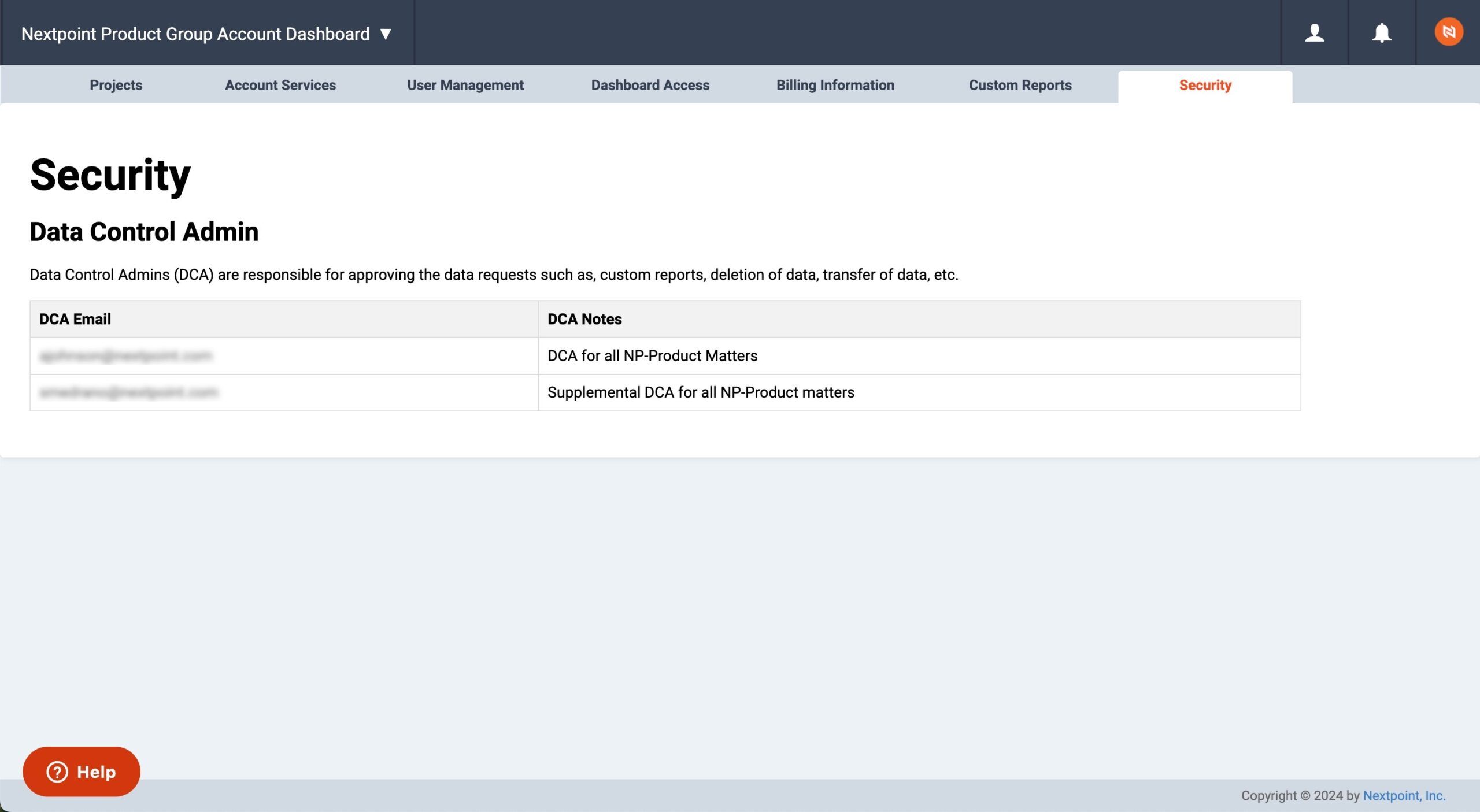
Take Control of Your Data
Nextpoint is launching a new Data Control tab for account admins, which gives you centralized control over your data and adds an additional layer of protection when requesting changes to your data. You’ll be able to designate a Data Admin for your account, who can see and approve requests from your team, such as archiving or deleting data.
Questions? Feedback? Please contact our team at support@nextpoint.com.
Streamlined Data Collection and Seamless Transcript Management
The evolution continues. Here are the latest enhancements to your ediscovery and case management software.
This week, we launched several new features that empower our users to operate seamlessly in a digital litigation landscape. See below for a preview of what’s included.
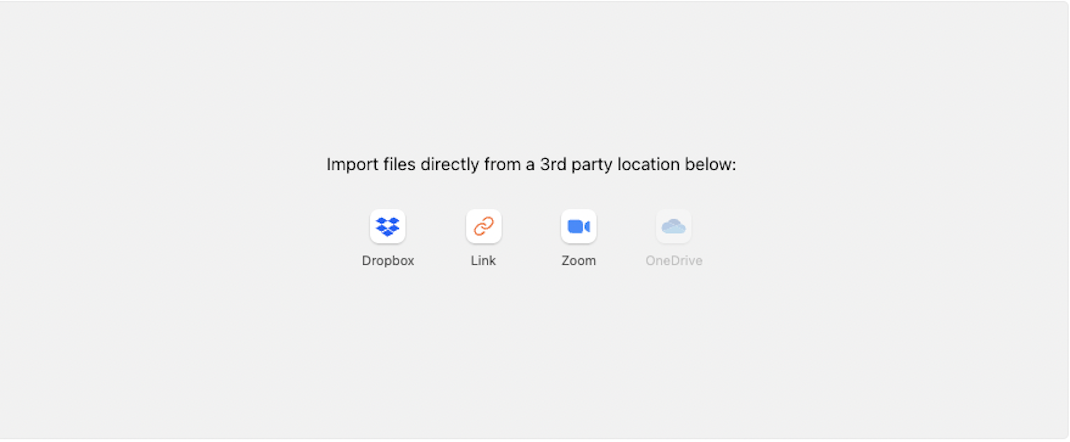
New Cloud Integrations: Live and Work in the Cloud
Earlier this year, we launched our cloud storage integration feature, which enables users to import data from popular cloud platforms with a few simple clicks. This feature has now been expanded to include Zoom and Direct Links, in addition to Dropbox.
Users can easily upload any Zoom data into Nextpoint, including audio recordings, video recordings, and transcripts. Direct Links, or Public URLs, are links that lead directly to a file instead of a web page. Users can paste these links into the file room and immediately access the data in Nextpoint. The Direct Link option also works with individual files from Google Drive.
Our goal is to make it easier for our users to live and work in the cloud. These new import options make the data collection process quicker and easier, so you don’t have to wait to start analyzing your evidence and building your case.
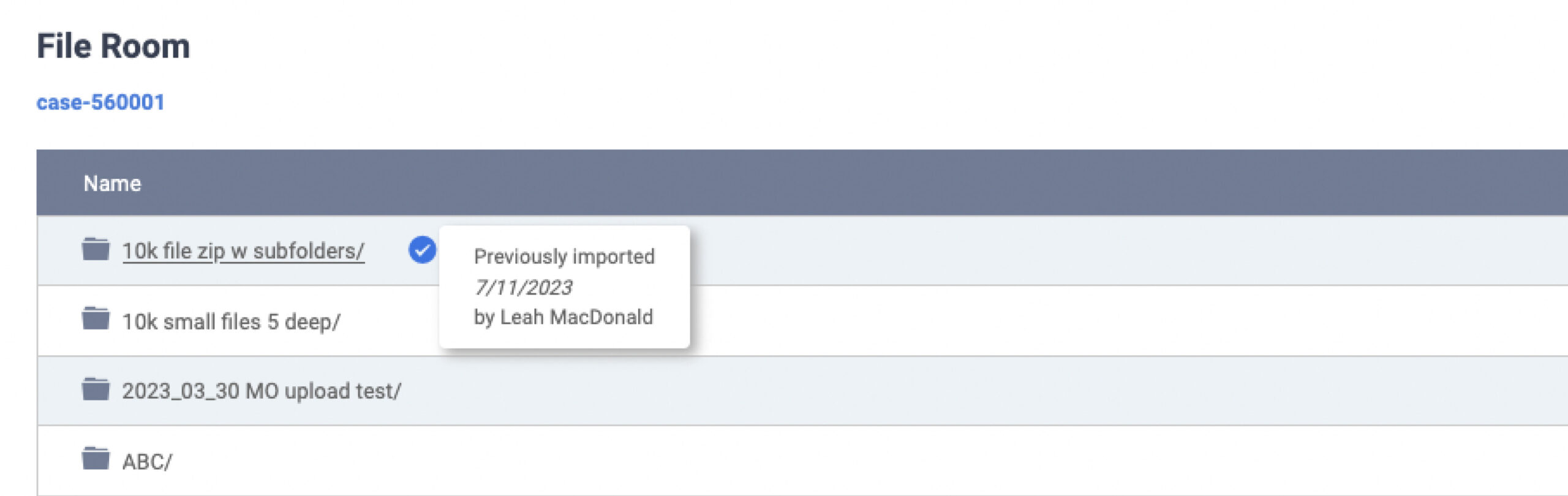
More Info on Imports for Smoother Data Collection
We updated the file room to help users keep track of their previous imports and streamline the data collection process. Any folder that has already been imported will be marked with a blue check mark. When you hover over the check mark, you’ll see when it was imported and who imported it.
This feature will help users avoid duplicative processing efforts and keep track of data that still needs to be imported. With the huge data volumes common in litigation today, we want to make it as straightforward as possible for our users to manage and organize their datasets.
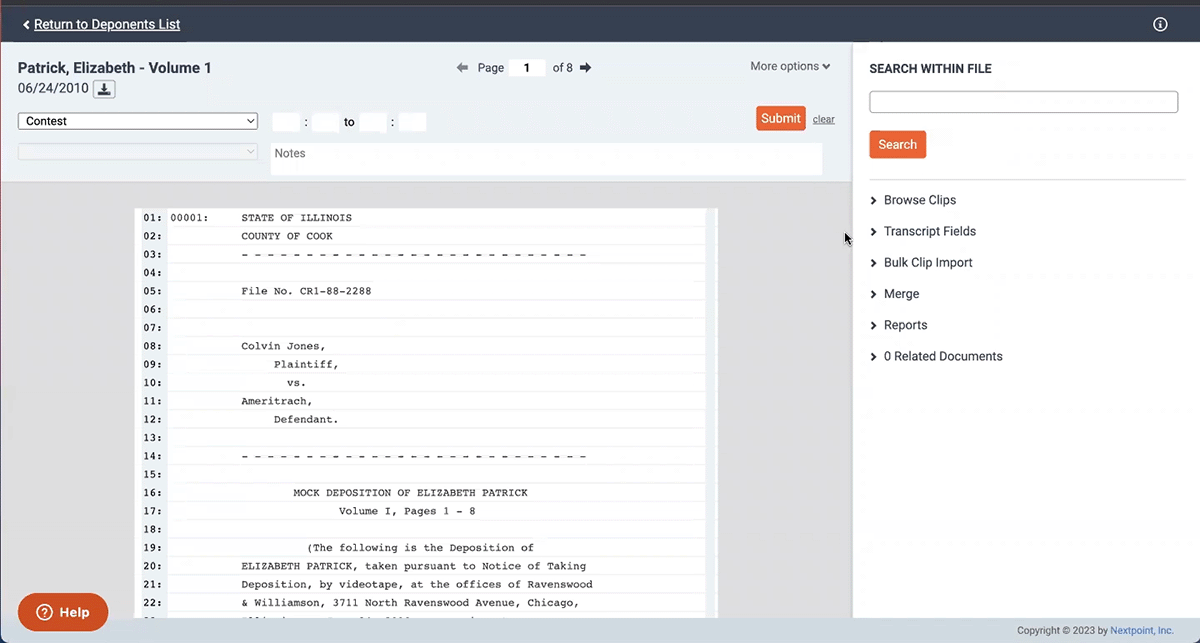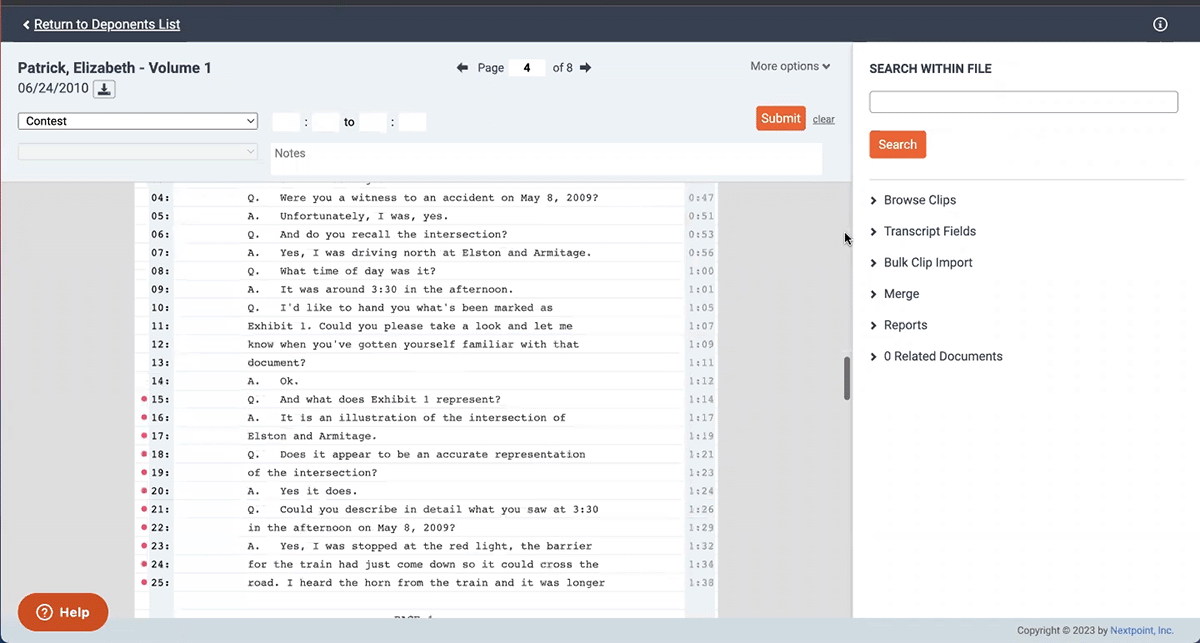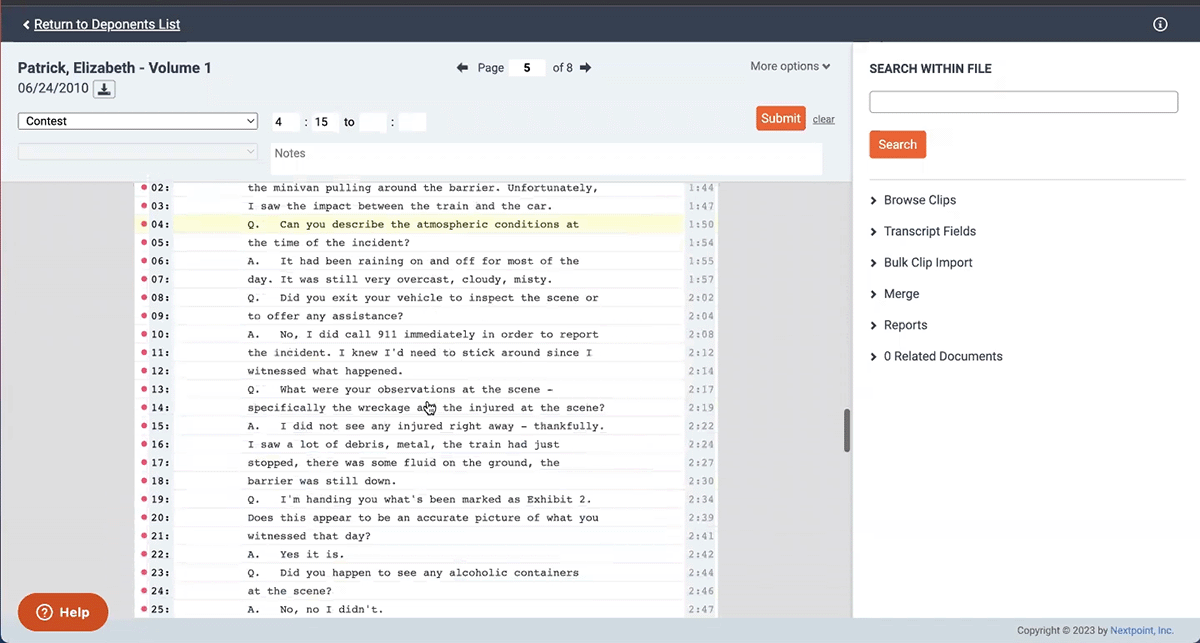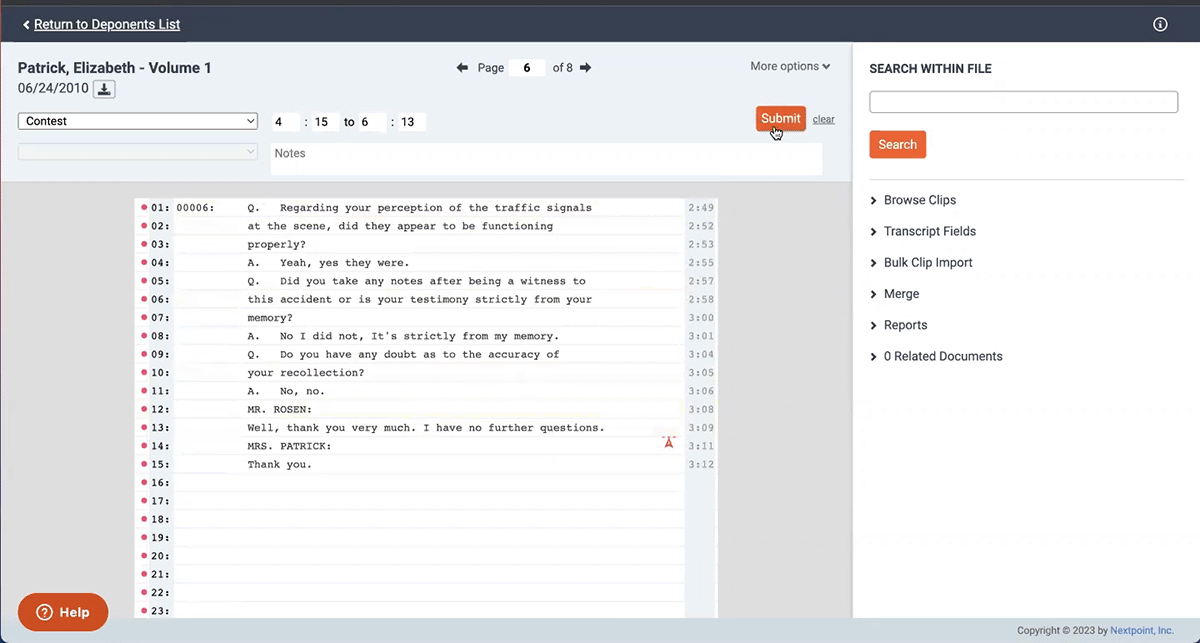
Analyze Transcripts Seamlessly with Infinite Scrolling
Analyzing deposition transcripts should be a seamless experience. That’s why we added “infinite scrolling” to our transcript management tool. Instead of clicking through each page of testimony, you can scroll through the transcript without interruption.
We want your experience in Nextpoint to feel natural and intuitive. The pages of a deposition transcript are part of a single flow of conversation – and now, the interface for transcript analysis reflects that feeling.
Transcript Reports Deliver Comprehensive Analysis
Context is everything when building a legal case. We added a new feature in our transcript management tool that enables users to include additional context when exporting Search Hit Reports.
Search Hit Report allow users to run keyword searches and export the highlighted search hits. Now, users can also choose to include up to 10 pages before and after the highlighted hit in their report. With this additional context, our reporting tools provide the foundation for a full comprehensive analysis.
Questions? Feedback? Please contact our team at support@nextpoint.com.
Enhancing the Full Litigation Lifecycle: From Redactions to Transcripts
The evolution continues. Here are the latest enhancements to your ediscovery and case management software.
We recently launched exciting new features that enhance the full litigation lifecycle, from discovery to depositions and beyond. See below for a preview of what’s included.
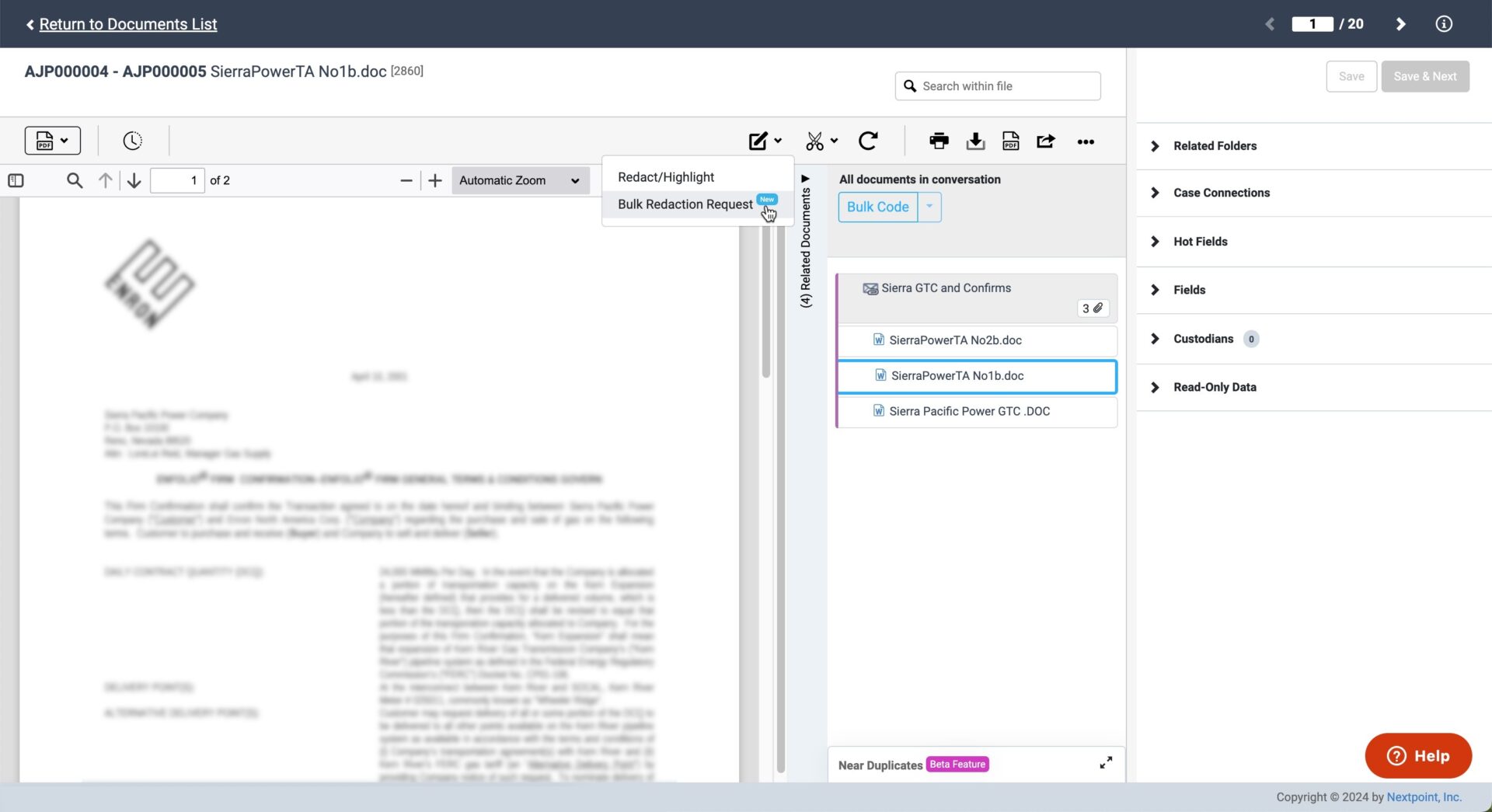
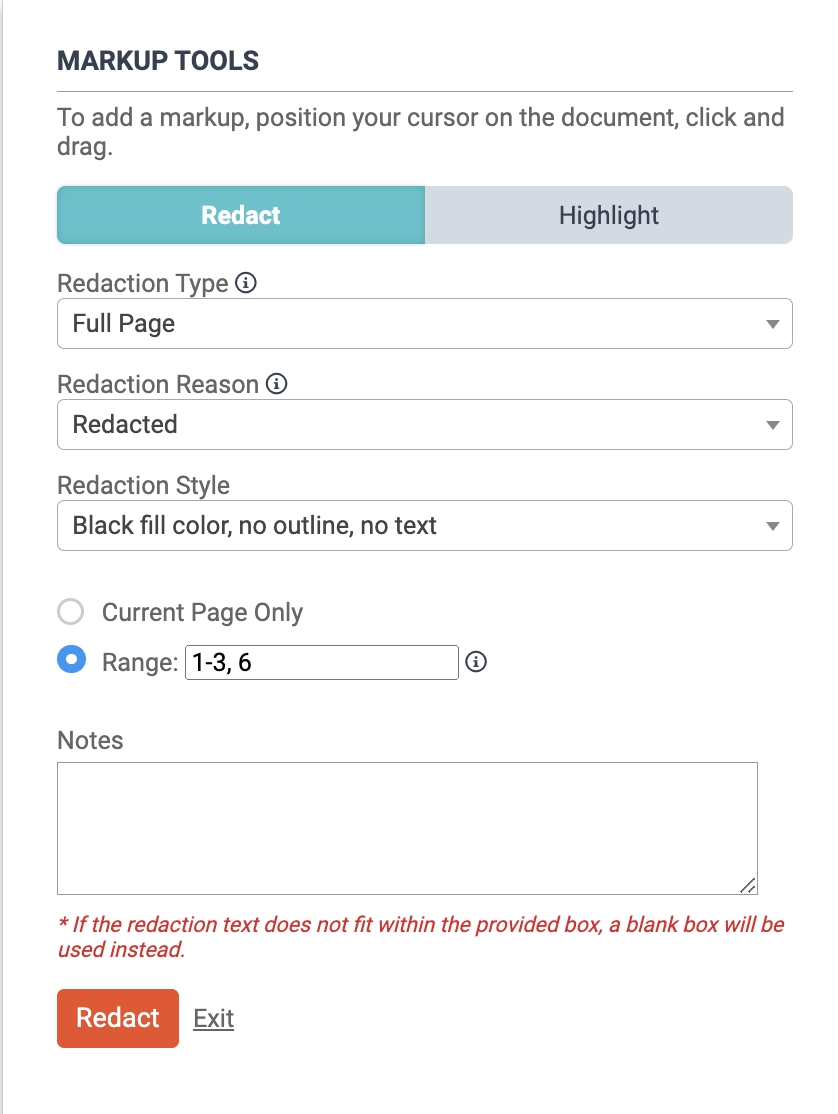
Automate and Streamline Redactions
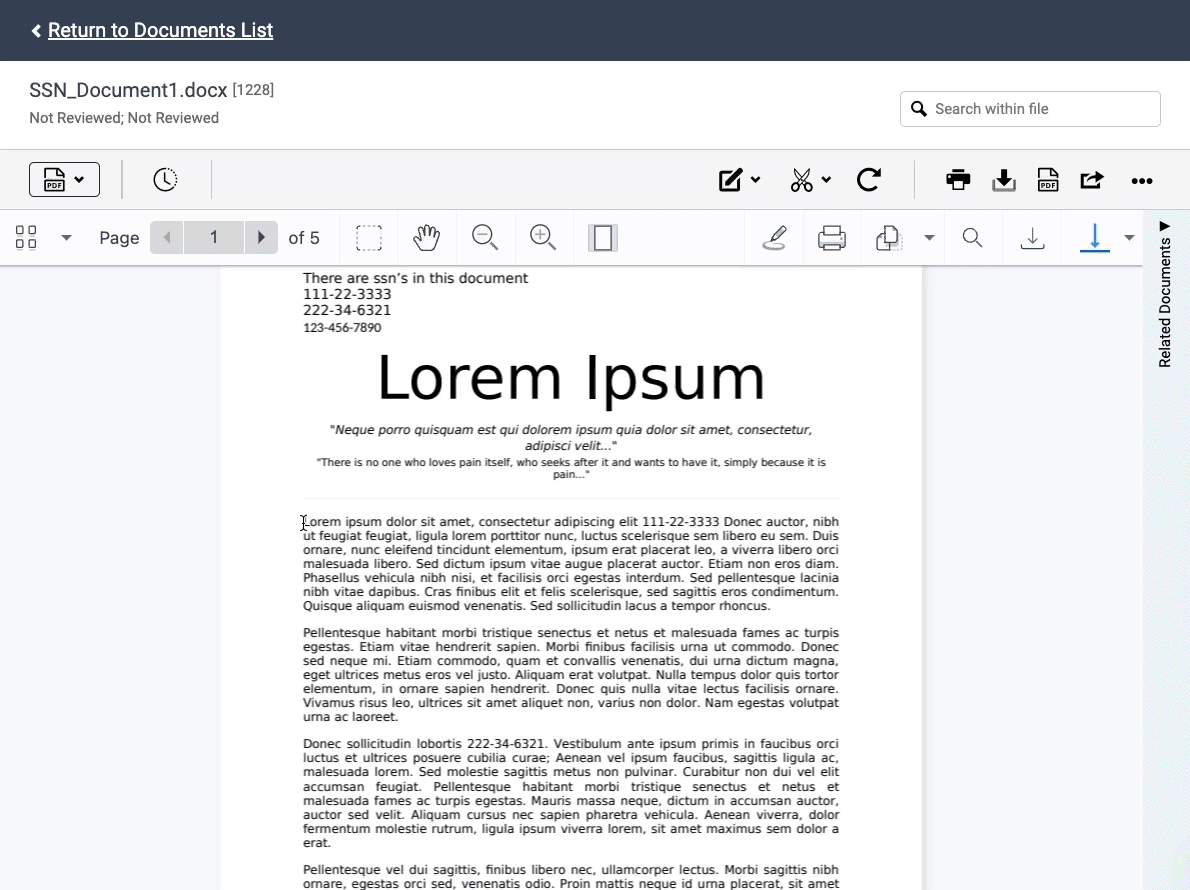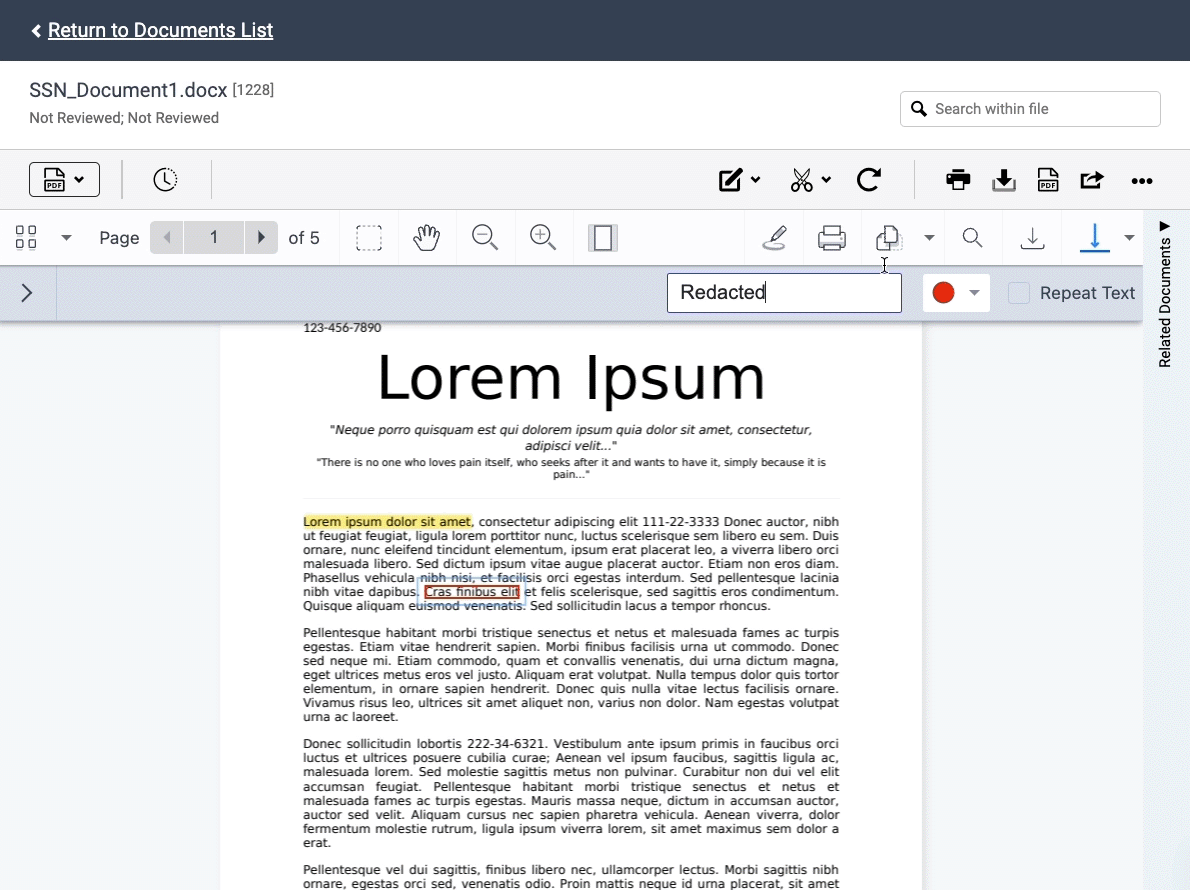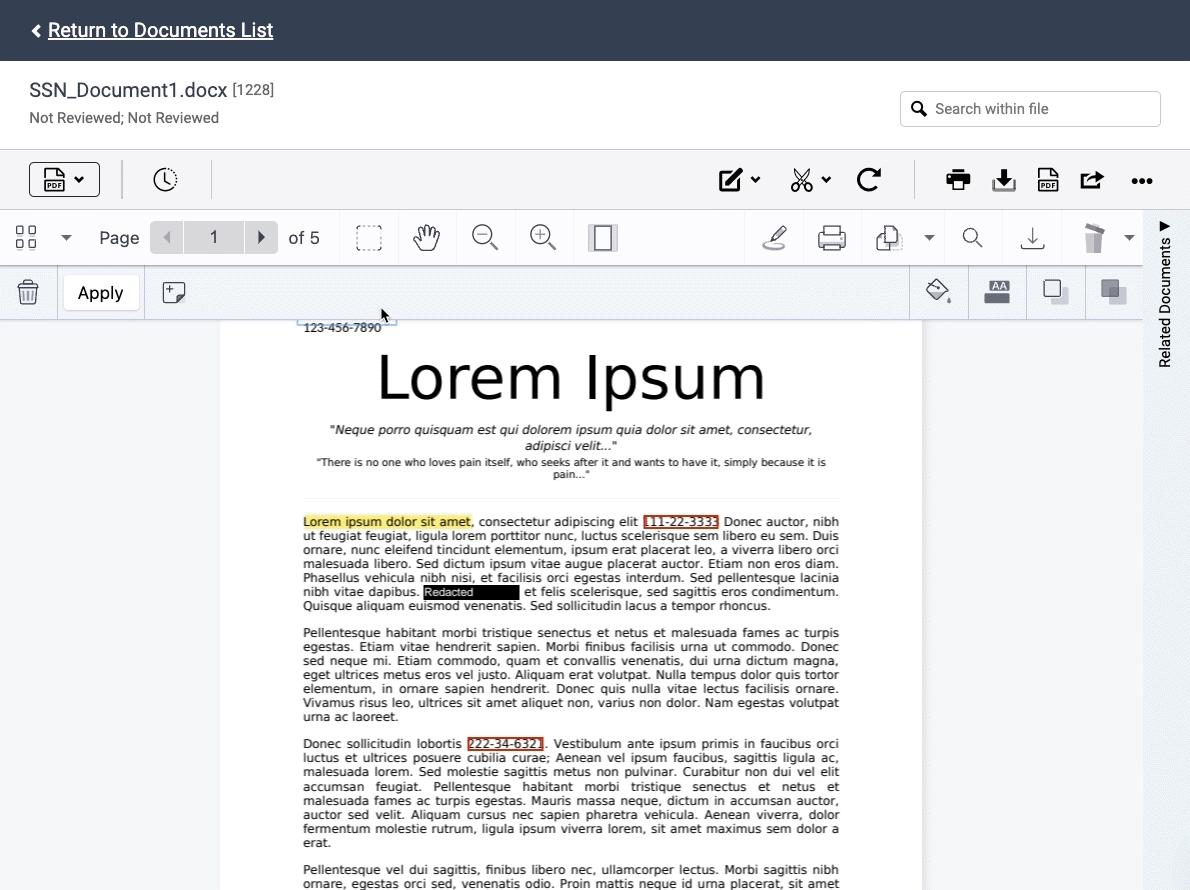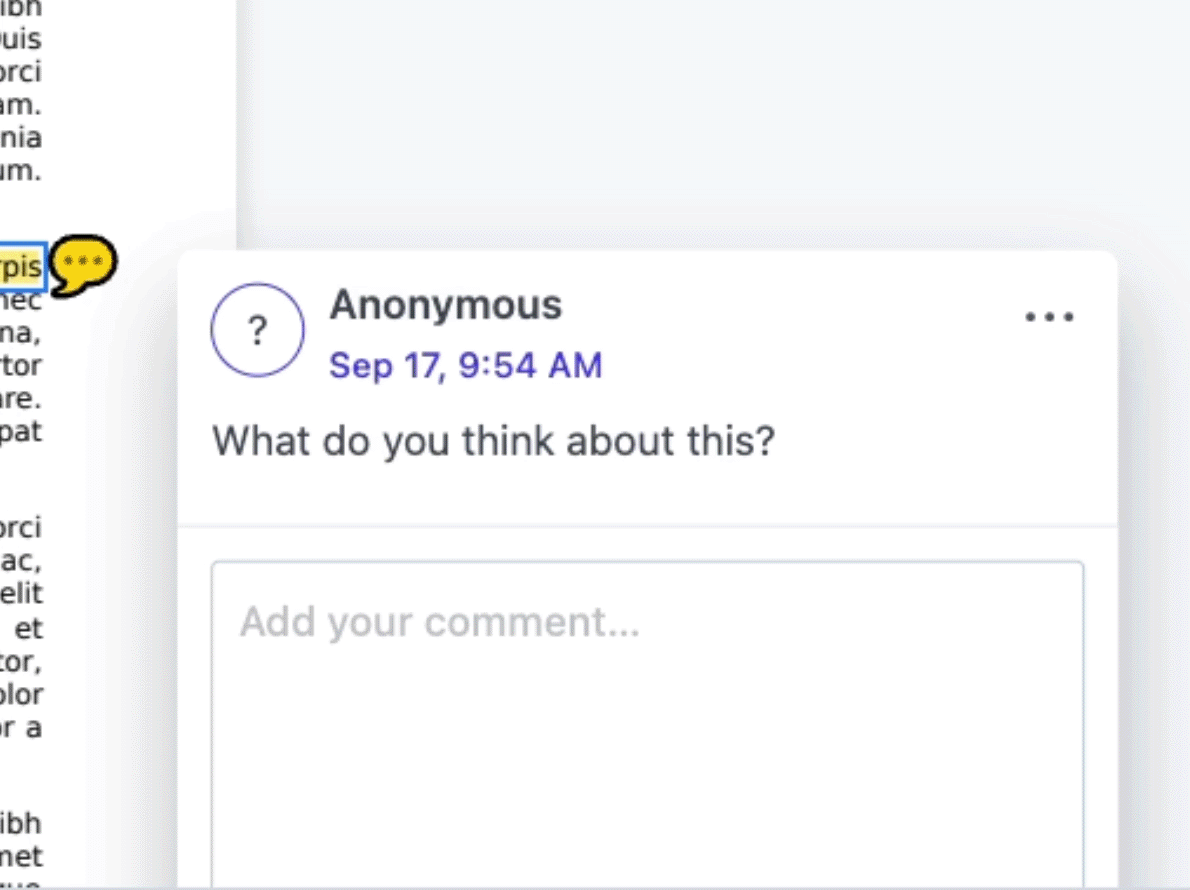
Redactions require careful attention to avoid disastrous consequences, like inadvertent waiver of privilege. But the manual process of marking each document can be time-consuming and tedious. To streamline this process, we launched Auto Redactions, a smart machine learning technology that can detect and redact sensitive information.
The Auto Redaction tool can find PII, or Personally Identifiable Information, in your data set, and apply the redactions automatically. This covers information like social security numbers, taxpayer identification numbers, and employer identification numbers. You can also create a list of specific terms that you want to redact across a set of documents.
Auto Redactions will be offered as a managed service with Nextpoint’s Data Services Team, enabling us to implement quality control measures and ensure the redaction project meets the individual needs of your team. You can submit an Auto Redaction request in the image markup tool in the document viewer.
Greater Complexity in Transcript Analysis
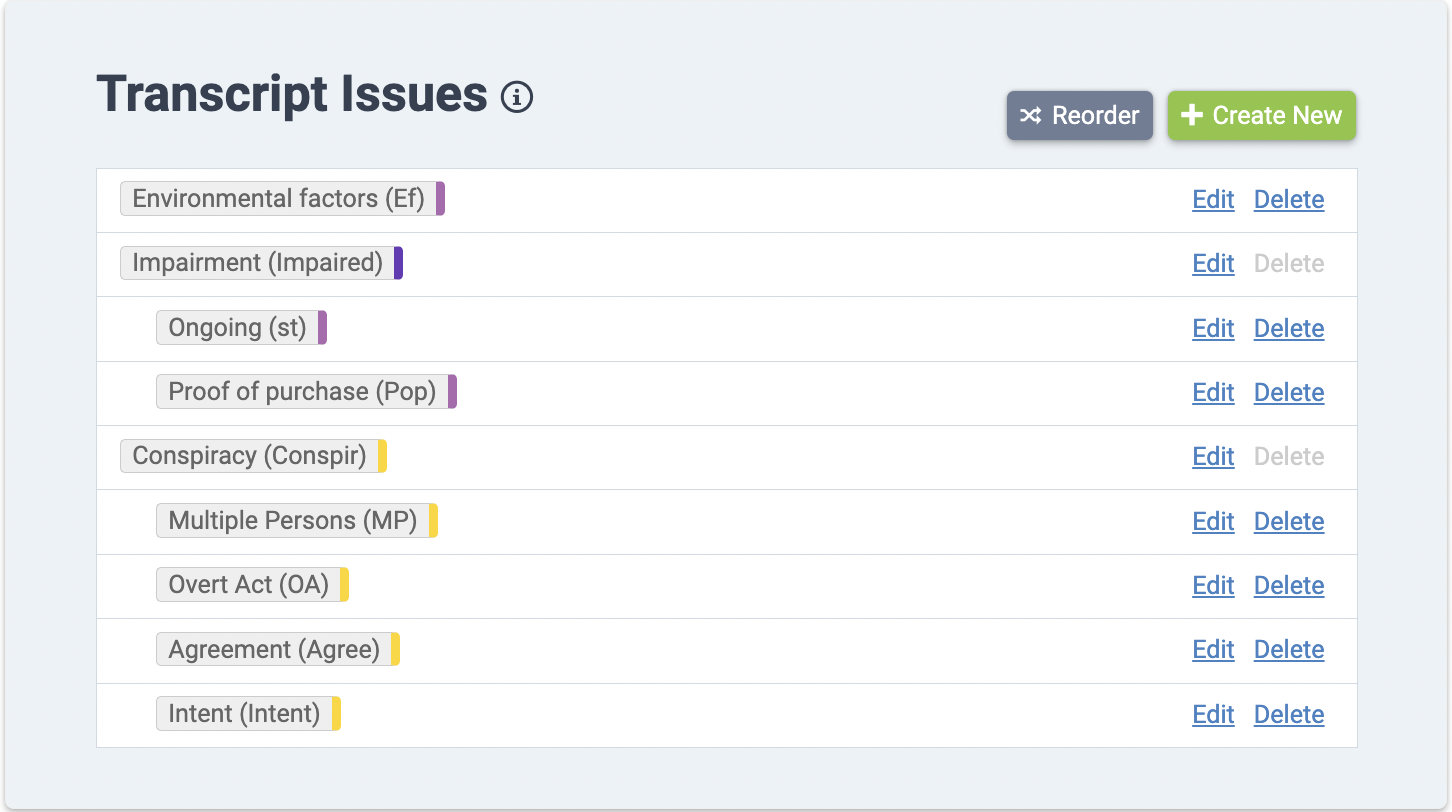
Building a legal case ultimately comes down to one simple task: Tell a compelling story. But the elements and details of that story are complex and varied. As you parse through witness testimony – a key building block of any case narrative – your tools should reflect that inherent complexity.
Now, Nextpoint users can incorporate a detailed taxonomy into their transcript analysis using parent and sub-issues and designations. As you evaluate, organize, search, and generate reports on deposition transcripts, you can easily see the connections between different – but related – aspects of your case. This is especially useful in large, complex matters, like multidistrict litigation.
Enhanced Transcript Reporting
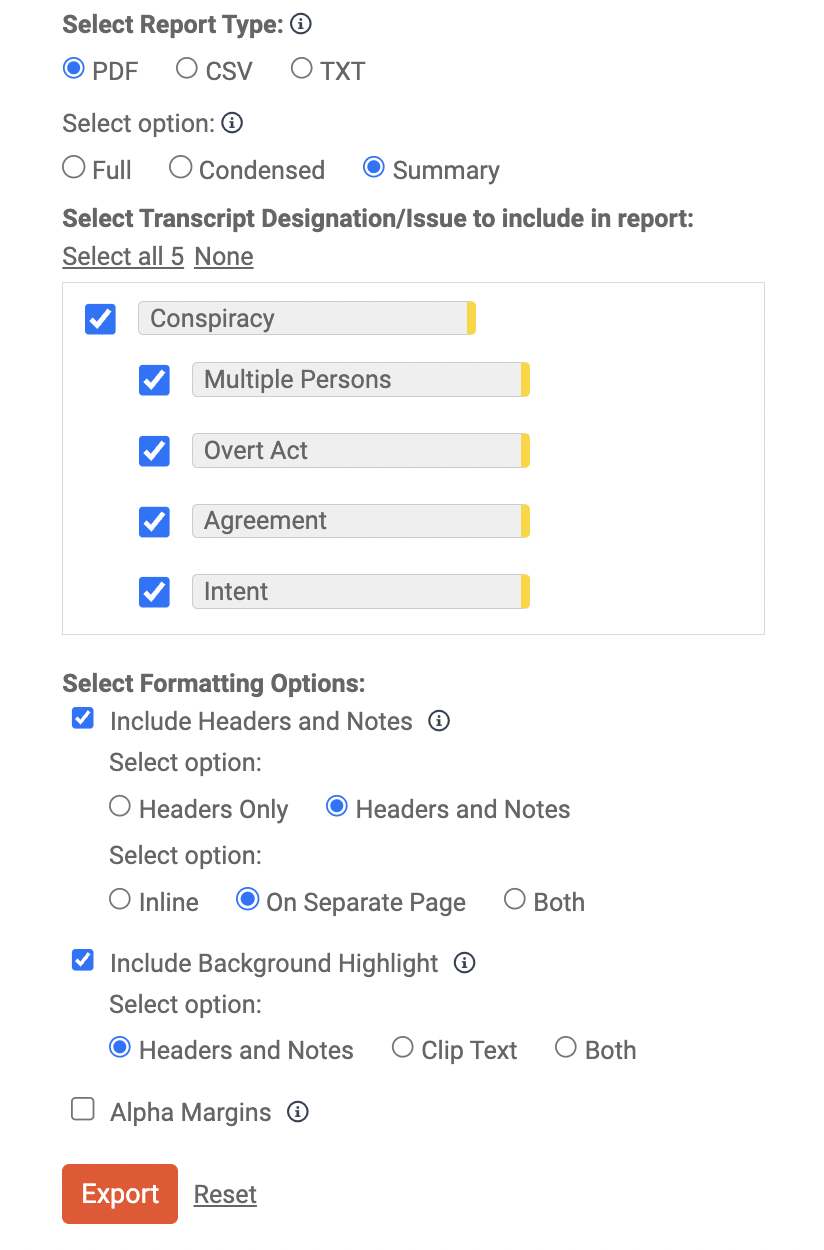
Analyzing and annotating transcripts in Nextpoint is only one part of working with witness testimony. Users can also generate various types of transcript reports when they’re ready to take their work outside of the Nextpoint platform.
We updated the transcript reporting feature to allow for greater customization as you build reports. For example, you can choose to include or exclude page and line numbers in the text of your CSV report. If you want include your designations and notes in a PDF report, you can choose to view them in line with the text, on a separate page, or in both locations.
We also added additional information to the “tool tips” so you know exactly what you’re getting with each report and each customization. Just hover your mouse over the little “i” to learn about your options and build a report perfectly catered to your needs.


Questions? Feedback? Please contact our team at support@nextpoint.com.
New Tools for Automation and Collaboration
The evolution continues. Here are the latest enhancements to your ediscovery and case management software.
We recently launched exciting new features that foster better collaboration, enhanced automation and smoother workflows for document review and case building. See below for a preview of what’s included.
Automate and Streamline Redactions
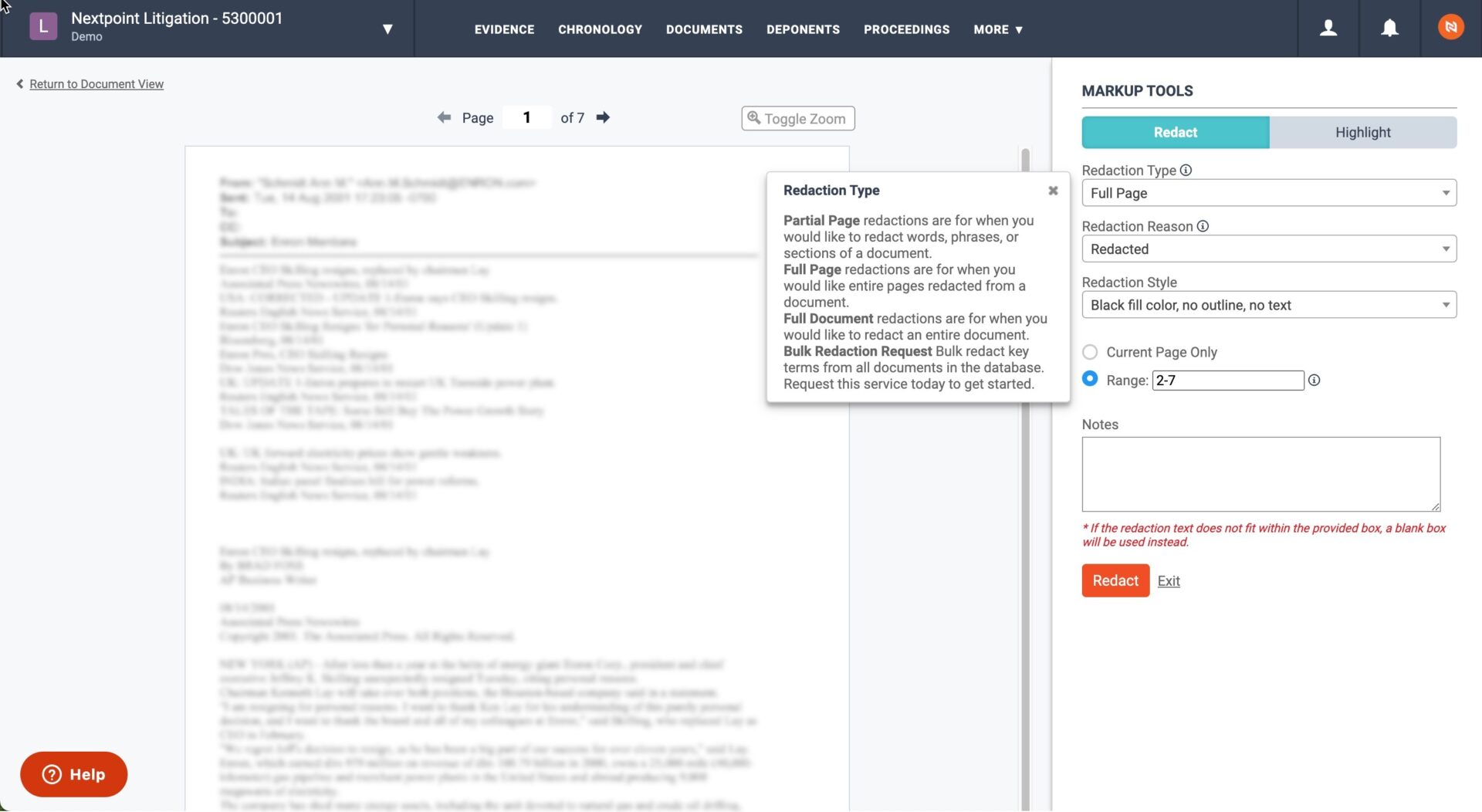
Redactions require careful attention to avoid disastrous consequences, like inadvertent waiver of privilege. But the manual process of marking each document can be time-consuming and tedious. To streamline this process, we launched Full Page and Full Document Redactions, the first in a new series of tools that will automate redactions while improving accuracy.
Cases often include long documents that require many pages of full redactions. Now, users can redact all of these pages at once; simply add a list of page numbers and watch the redactions appear in your document. Users can also choose to redact an entire document at once, like a privileged email attachment that must be produced because it’s part of a responsive email family.
Stay tuned as we continue to enhance your redaction toolkit with automated, reliable methods to speed up your review process.

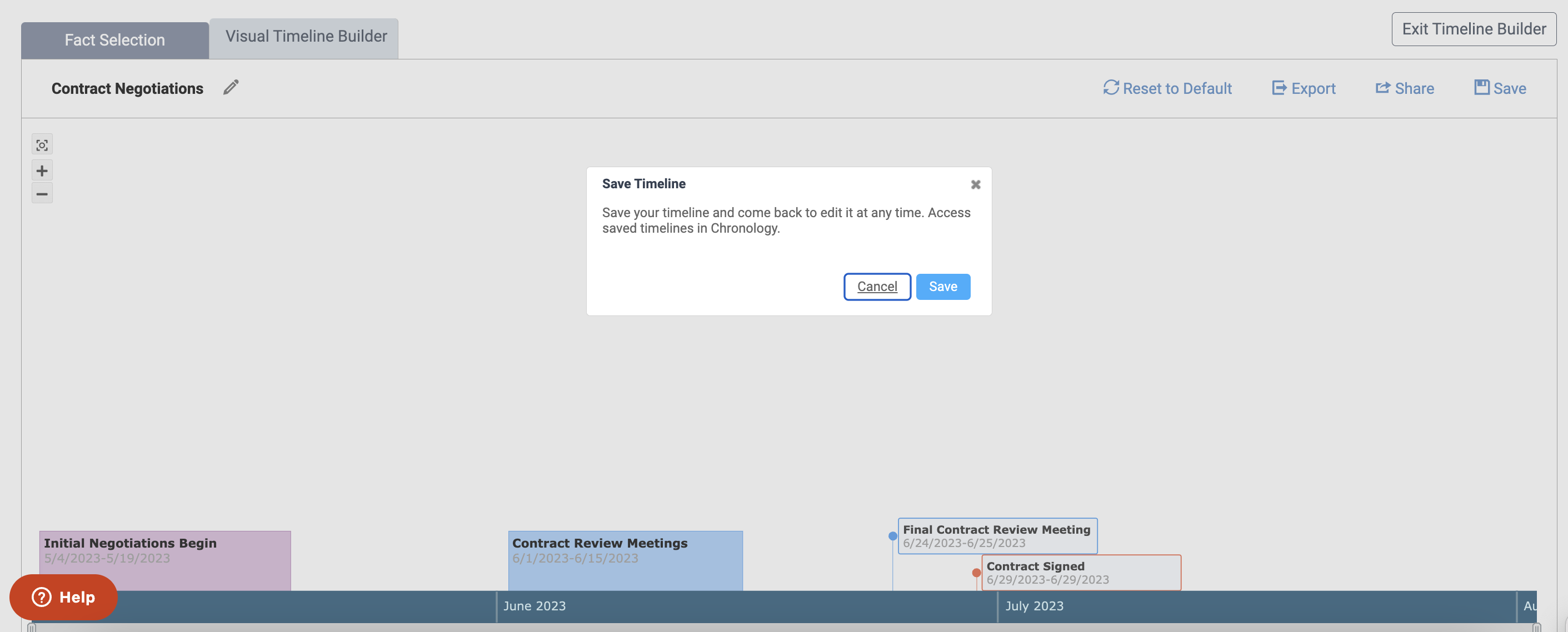
Refine and Collaborate On Your Visual Timelines
This year, we launched many exciting updates in our Litigation platform to help users build their winning case story, including the Evidence Dashboard, Case Chronology, and Visual Timeline Builder. In the initial Timeline launch, users could export their timelines as PNGs or PDFs; now, they can also save, edit, and share their timelines to collaborate with other members of their team.
One of the biggest advantages of working in the cloud is the ease of collaboration; now, this extends to visual timelines, an essential tool for legal teams working together to build a complex case. We also want Nextpoint to be a living space where users can develop, refine, and analyze their cases, and we knew that the ability to save and edit timelines is essential to this goal.
Quick Wins for Case Building
With all the exciting additions we’ve made to the Litigation suite this year, we’ve been constantly listening to our users to understand how we can refine these features and provide an optimal experience. Here are a few small updates that will enhance case building in Nextpoint:
- Fact, Issue, and People Overlays: In Nextpoint, users can utilize “overlay” CSV files to update the coding and metadata of documents in their database. We added the overlay capability to Facts, Issues and People so that it’s easy to migrate case building workflows to Nextpoint and manage them right alongside discovery and depositions.
- Facts and People in Searches: We added Facts and People to Advanced Searches as well as autosuggestions in the search bar, giving users more ways to filter through the evidence using the key elements of their story.
- Refined Timeline Layout: We continued to refine the layout of the Visual Timeline Builder, including an adjustment to the location of the Help button. (Sometimes, the little things are what our users care about. So of course, we care about them too.)
Stay tuned in 2024 to see how we continue to enhance your case building experience. And don’t hesitate to reach out with any feedback – we love to hear your ideas.
Questions? Feedback? Please contact our team at support@nextpoint.com.
Simplify Your Data With Nextpoint’s New AI Tools
The evolution continues. Here are the latest enhancements to your ediscovery and case management software.
Legal data has increased in both volume and complexity, calling for a new generation of technology that intuits and adapts to the intricacies of our modern digital world. The new AI tools in Nextpoint offer a solution that streamlines the litigation process without sacrificing the quality of discovery and case prep.
Automated Analysis of Your Documents
A typical ediscovery caseload can include tens of thousands of documents – and sifting through each file one by one requires extensive time and resources. But skirting by document review can lead to critical consequences, like missing key pieces of information or inadvertently waiving privilege. Legal teams need automated solutions that mitigate the risk of discovery mistakes – you should never have to sacrifice accuracy for efficiency.
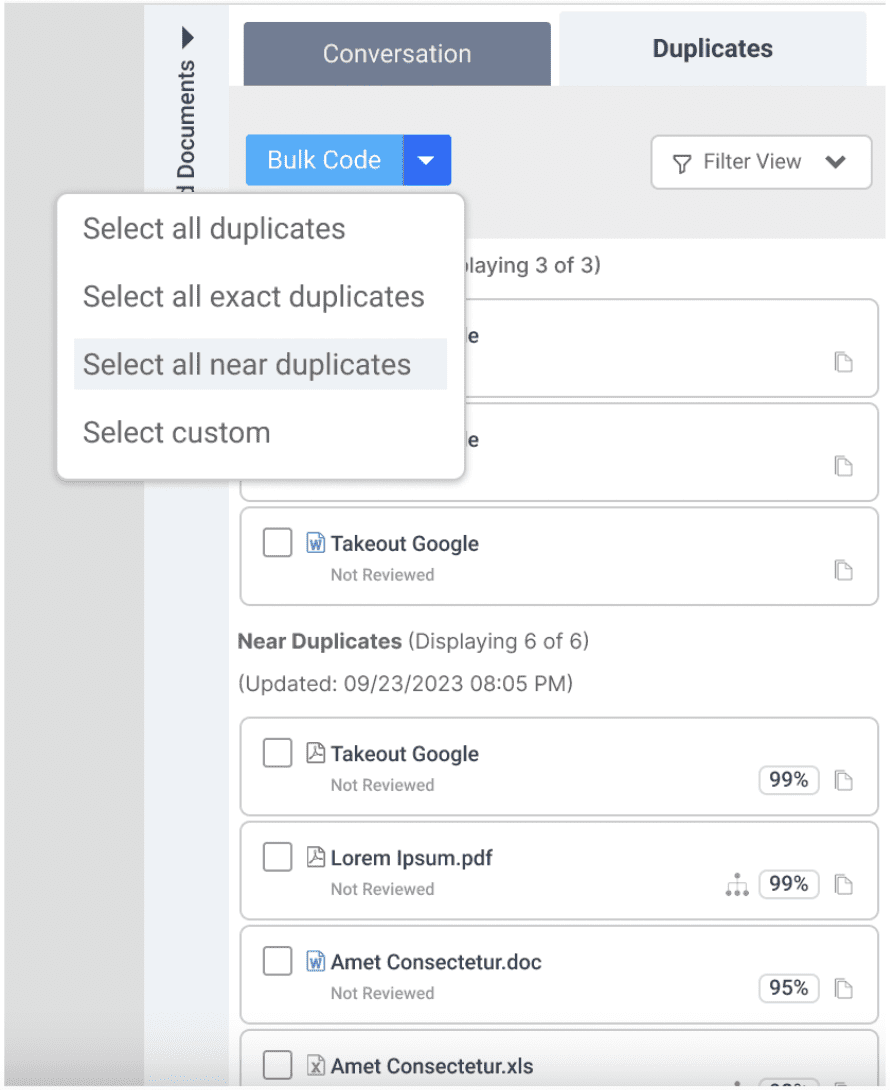
Within a huge set of ediscovery data, many documents will be virtually the same, with minor differences. Ever had deja-vu from reviewing the same document for the fourth time, only to realize it was sent over and over in a massive email thread? Those documents are known as “near-duplicates.” It’s like a new edition of a book, but all that’s changed is the foreword.
Now, Nextpoint software can identify and group near-duplicates together so that users can analyze and code them in one sweep, without wasting time reviewing repeat documents. Each duplicate includes a similarity score indicating how similar it is to the original document, which enables users to make informed coding decisions. It’s automated and efficient, but the power still lies in the irreplaceable judgment of the reviewer.
Our skilled team of developers engineered a complex machine learning algorithm designed to maximize accuracy and speed while minimizing costs. Nextpoint Law Group is here to help users understand the nuances of this technology and implement custom solutions to ensure near-duplicate analysis meets the intricate needs of every case.
Utilizing near-duplicate analysis
| Contract Analysis | Evaluate progressive versions |
| Nonstandard ESI | Evaluate Hard copy files or other files without metadata |
| Disorganized Document Collections | The same documents provided multiple times in varying formats |
| Analyze Email Attachments | Compare similar documents attached to varying correspondence |
| Hot Docs | Identify documents similar to the key evidence in your matter |
| Validate Coding Consistency | Double check similar documents that are coded differently |
| Privilege Protection | Easily review documents similar to those marked “privileged” |
| Document Productions | Track and compare the same documents produced by different parties |
| Deposition Prep | Compare which preceding depositions utilized similar document evidence |
| Multidistrict Litigation | Track similar documents produced and/or utilized in a deposition across cases |
Intelligent Search Tools: Go Beyond the Keyword Query
In most litigation today, users have to sift through a mountain of potential evidence to find the relevant documents, and the first method in their toolkit is a simple keyword search. But a keyword search won’t work on all the evidence a litigator might see in 2023.
That’s why we added advanced Machine Learning features to Data Mining – to make the unsearchable, searchable. Users receive deeper insights into their data and can easily comb through images, audio files, foreign language text, and handwritten documents, alongside the rest of their data.
Here are the four new types of Machine Learning analysis users can take advantage of in Data Mining:
- Image Recognition: Images will appear in search results based on the contents of the image. Our complex analysis means that an image of a bridge could show up in searches like “bridge,” “construction,” “construction site,” “infrastructure,” etc.
- Handwriting Recognition: This feature will detect, read, and extract handwritten text so that it can show up in search queries. While most legal data today is produced electronically, plenty of litigation involves meeting notes, calendars, and other handwritten documents. You don’t want to lose those relevant analog materials in a sea of ESI.
- Transcription: Video and audio files will be transcribed, allowing the contents to appear in searches. For example, you could search the word “profit” and find emails discussing profits as well as a recording of a Zoom meeting where profits were mentioned.
- Translation: Foreign language documents will be translated to English, which means you don’t have to run searches in multiple languages. Simply search a term like “contract” and see all the matches in English, Spanish, German, or any other language populating your database.
These features eliminate time-consuming manual processes while ensuring you have the tools to find your smoking gun, no matter what form it takes.
Slice Up Your Data Seamlessly
It’s not enough for all your data to be searchable – in order to find that needle in a haystack, you need robust search tools that enable you to filter and organize your data with ease.
In Data Mining’s new Slice Builder, users can stack various criteria to build complex searches in just a few clicks. By combining factors like search terms, custodians, imports, and file types and properties, you get more than just search results – it’s a “slice” of your data that you can save, share, and analyze using Data Mining’s visual reporting features.
Paired with advanced Machine Learning analytics, the comprehensive Slice Builder offers endless ways to organize, understand, and interpret your data.
See Nextpoint AI in Action
Talk of AI chatbots and image generators has flooded the internet – and the legal tech world. But these GenAI tools have a long way to go before they can be a strong asset for legal teams. Nextpoint’s AI technology utilizes trusted algorithms that have been developed and tested specifically for legal cases, complete with comprehensive security measures and quality controls. With our AI tools, you’ll see tangible solutions to the challenges you’re facing today.
Reach out to your client success director to take advantage of near-duplicate analysis, Data Mining machine learning, and more advanced Nextpoint features. Or, schedule a chat with Nextpoint Law Group to consult with our legal data specialists about the unique needs of your case.
Questions? Feedback? Please contact our team at support@nextpoint.com.
Seamless Case Building: Tell a Visual Story
The evolution continues. Here are the latest enhancements to your ediscovery and case management software.
This week, we launched exciting new features that empower our users to seamlessly build a compelling case story. These updates build on our summer product launch, where we added the Case Chronology tab and Evidence Dashboard. See below for a preview of what’s included in the new release.
See Your Story As You Build It
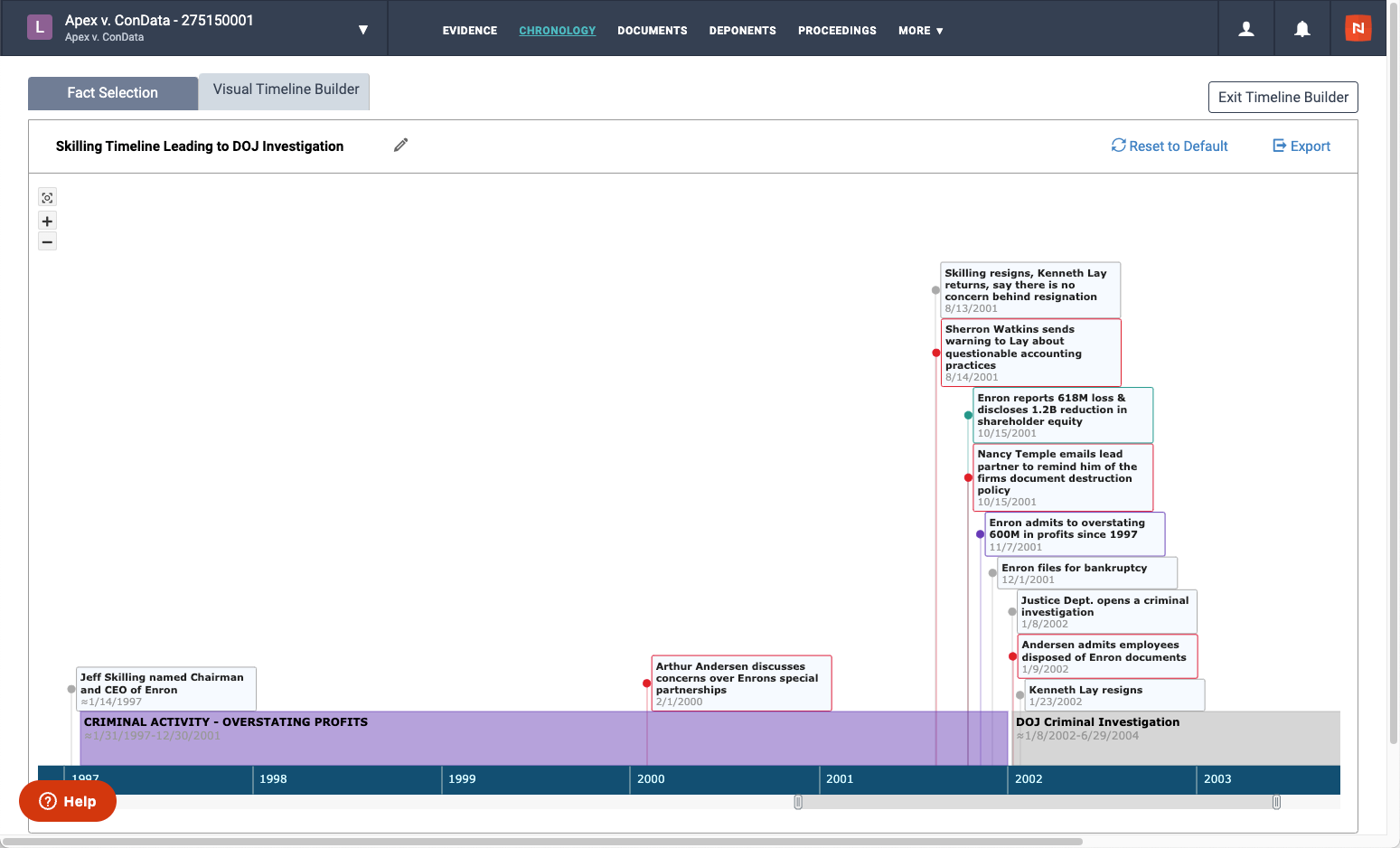
The key to a winning case is a compelling story – which starts with a cohesive timeline of events. In July, we revamped our Litigation platform to make it easier for our users to build that winning story. Now, you can transform your case narrative into a visual timeline, armed with the tools to see your story as you build it.
The new Visual Timeline Builder enables users to see the facts of their case laid out as a chronological narrative. You can choose to lay out the entire case, or hone in on a specific issue; you can also customize the colors and information displayed on your timeline.
A timeline breaks down the complexities of your case in a way that’s easy to understand, helping you discern the core components of your argument. Then, you can export it and share it with your team, witnesses, judges, jury, opposing counsel – it’s a visual aid for you to build and share your story.
Building Complex Case Connections
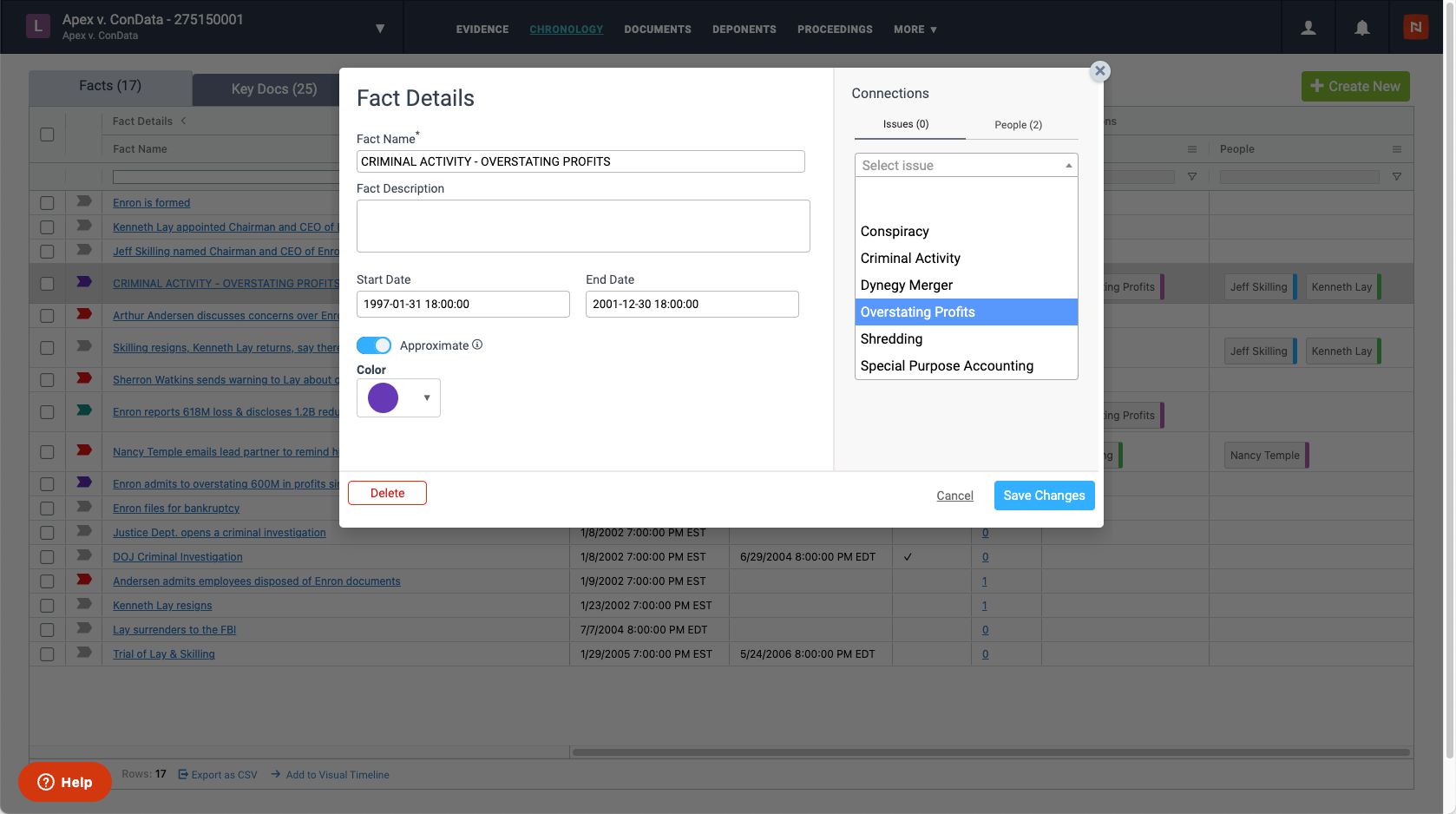
The key elements of a story are relatively simple, which is why Case Chronology breaks down your case into three components: Issues, Facts, and People. But these basic components encompass a multitude of complex details, relationships, and evidence.
Case Chronology has moved a step further in reflecting that complexity, empowering users to draw deeper connections between the various elements of their case. Now, users can connect Facts, Issues and People to one another and view these connections in their Chronology grid.
For example, if you’re preparing for a deposition, you can easily examine all the facts and issues associated with that individual. If you want to hone in on a specific issue, you can view all the relevant facts and quickly understand where you stand on that issue. Case Chronology gives you the tools to build a comprehensive picture of your story and capture all the complexities of your case.
Questions? Feedback? Please contact our team at support@nextpoint.com.
Better Tools for Building Your Case
The evolution continues. Here are the latest enhancements to your ediscovery, case management and trial prep software.
At our Summer Product Launch, we announced major updates to our Litigation platform. See below for a preview of what’s included.
Build a Case That Tells a Story
The key to winning your case is crafting a compelling story. That’s the philosophy our experts have developed from their years of firsthand trial experience. Nextpoint’s new Case Chronology feature makes it easier for our users to build that winning story.
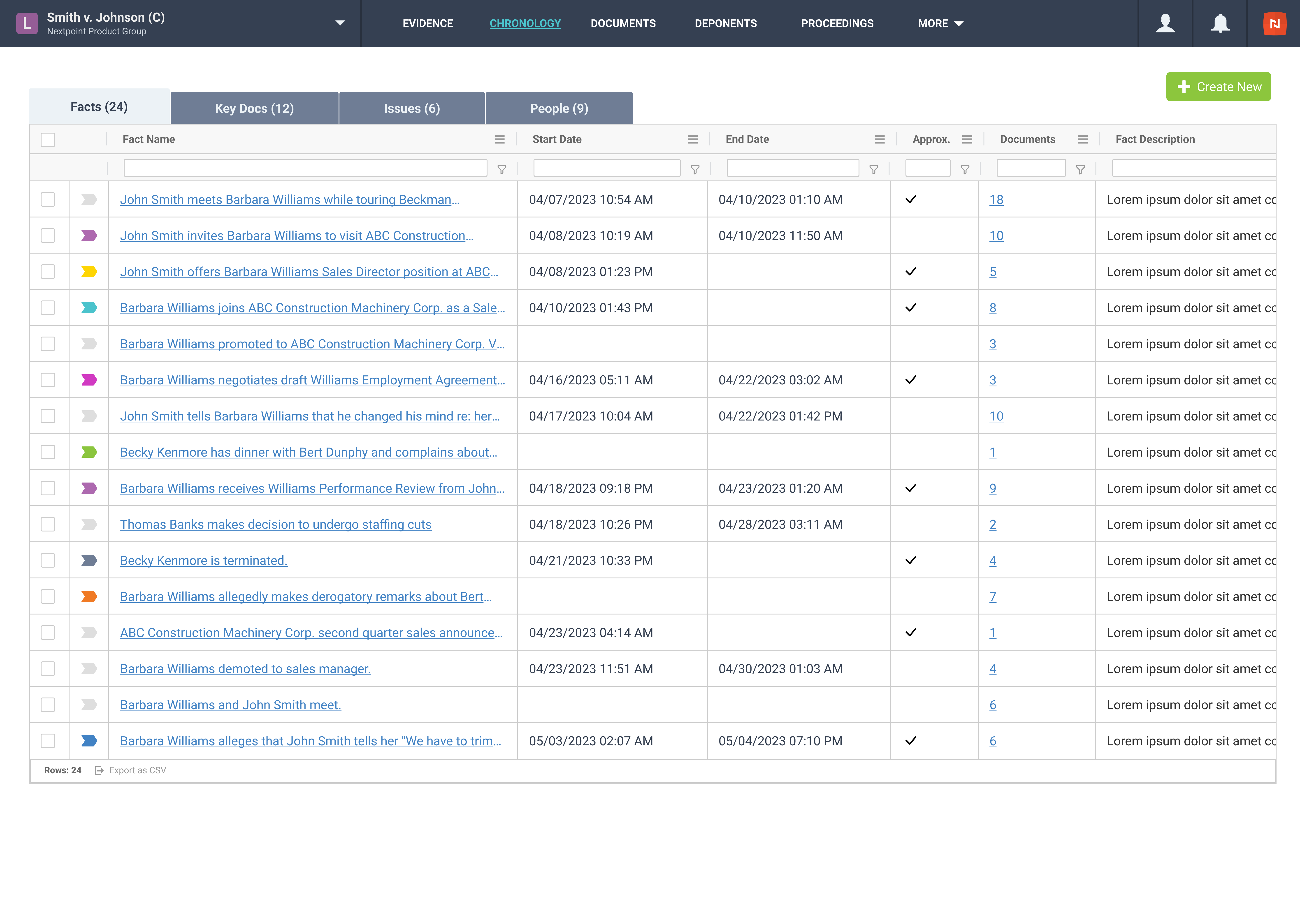
Case Chronology enables users to categorize evidence and frame ideas around the key elements of your case: Facts, Issues and People.
- Facts can be used to underscore the anatomy of a dispute, including important events, legal claims and defenses of each party.
- Issues are those vital questions of law on which the court must rule.
- People are important individuals or organizations in a matter.
After assigning Facts, Issues and People to pieces of document evidence, you can sort your Facts by date to view a chronological grid that depicts the case story and associated evidence.
These core building blocks exist in every case-building framework, no matter what tools legal teams use to assemble their argument. The main characters, key events and claims, linear timeline, and overarching themes come together to form a compelling legal case. Our new and improved Litigation platform now provides a clear and simple methodology to conduct this age-old case building process.
Watch Your Story Unfold Visually
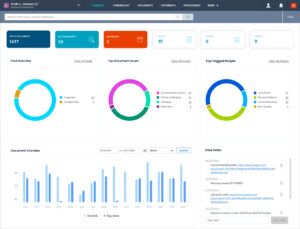
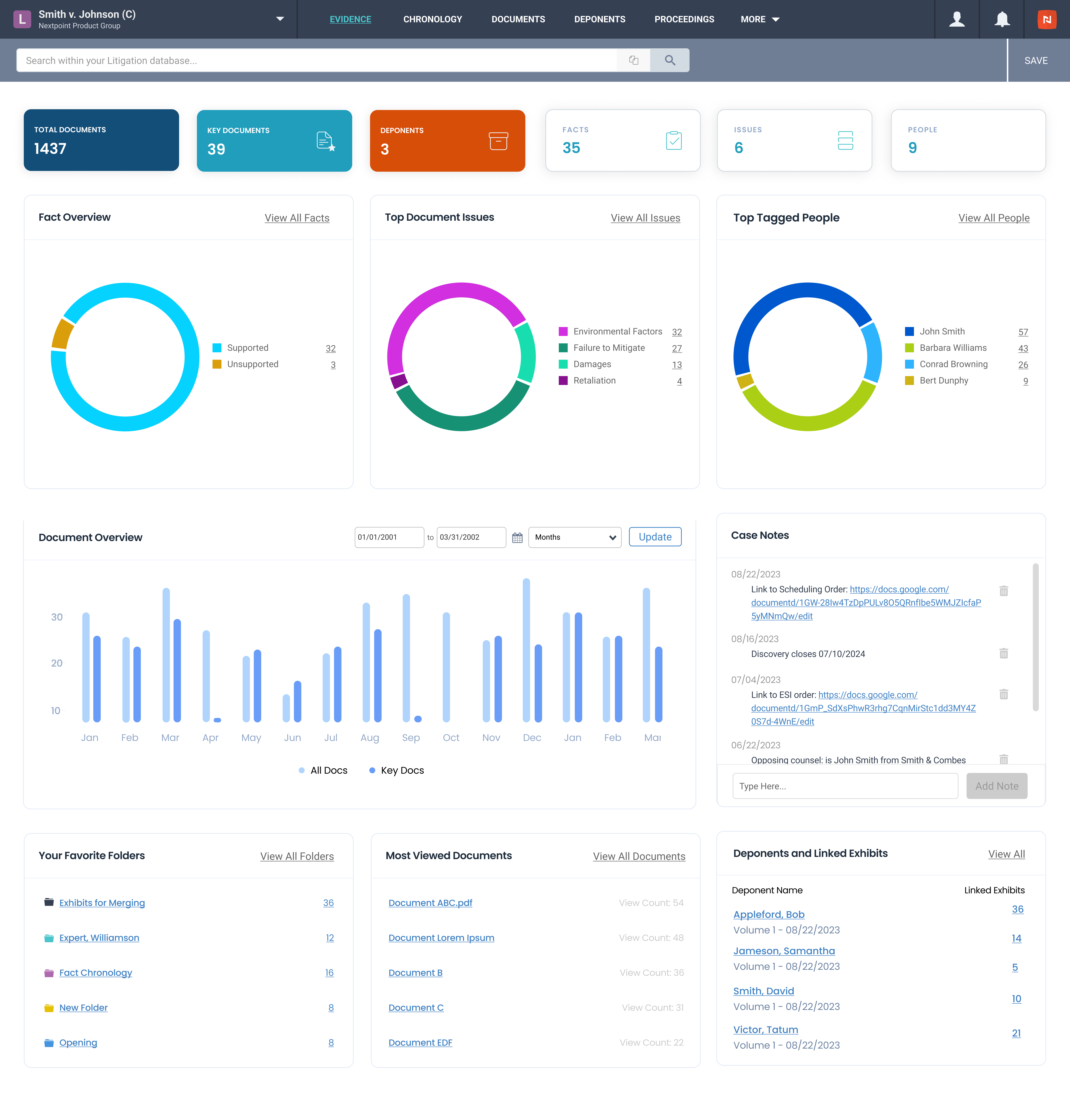
The new Evidence dashboard provides a visual space for users to watch their story unfold and track the progress of their case. The dashboard displays quick facts and figures on the evidence, including a Fact Overview, Top Document Issues, Top Tagged People, and Most Viewed Documents.
The “Favorite Folders” section is individualized to each user so that they can quickly access the documents most relevant to their work on the case. Users can also utilize the new Case Note feature to record thoughts, ideas, and resources that are shared with their team.
The Evidence dashboard brings together all the pieces of a complex case story in one location, enabling users to draw connections and view trends in the evidence. New understandings of the case arise effortlessly, while the story you build in Case Chronology comes together seamlessly.
A Software Solution for the Full Litigation Lifecycle
These updates are part of Nextpoint’s longstanding goal to provide a single platform that supports legal teams throughout the full litigation lifecycle, from Early Case Assessment to trial presentation. Nextpoint started out as a case building and trial prep software, and we want to ensure this initial purpose holds strong as we expand to the rest of the litigation process. Alongside our comprehensive deposition/transcript management tools, this launch will enable our users to keep all of their case building in one place.
This product launch is also another step in our goal to provide better support for digital legal proceedings. All of our launches this year have centered on this objective, and we’re excited to show you another round of exciting updates at On Point, our annual user conference. Stay tuned to sign up for On Point on September 20-22 and see the latest advancements in our suite of end-to-end litigation software.
Questions? Feedback? Please contact our team at support@nextpoint.com.