

Well, it’s that time of year again – Nextpoint has made our terrific product even better. Thanks in large part to your feedback and suggestions, our team has made a number of improvements to the functionality and workflow of our software. Take a look!
Searchable Folder Categories
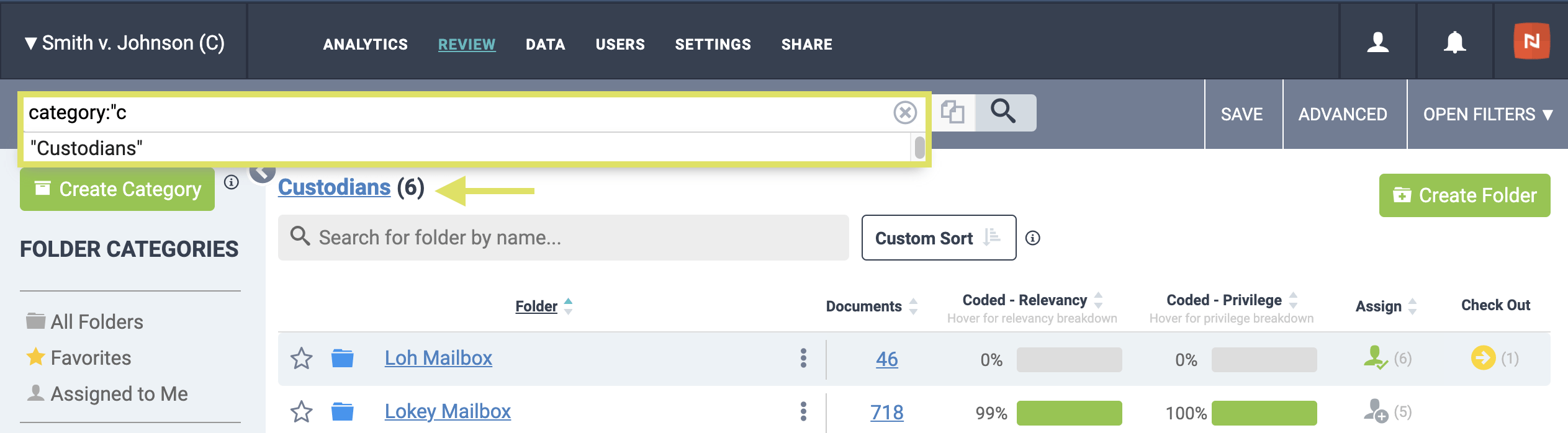
Folder Categories, which were first released in Fall 2020, are now searchable in your Nextpoint Discovery and Litigation databases. We introduced this functionality in an effort to provide efficiency gains to our user community when navigating multiple folders grouped in a category.
Now, when you are logged in to any Discovery or Litigation database, you can utilize the search syntax category:”category name” to return all documents associated with a particular category via their folder assignment. Searching for a particular category will translate on the back-end as an OR search across all folders within that category.
For example, searching for Category:”Productions” will return all documents within the folders associated with the Productions category, and the back-end syntax will translate as (folder:”prod1″ OR folder:”prod2″ OR folder:”prod3″).
To get started searching for documents associated with a particular Folder Category, you can use our auto-suggest functionality. Simply start typing category:” in the search bar, and all category options will be listed. Each category header is also hyperlinked at the top of your folder list and available for selection in Advanced Search.
For further information on searching, the Nextpoint Search Guide has been updated to reflect this new search syntax option.
Transcript Enhancements
Downloading original transcript files is easier than ever with readily accessible download icon links from any list in Deponents and Proceedings, and also within individual transcripts. Plus improved visibility into your transcript designation notes with the expansion of the text input box.
Processing Updates
The option to “Disable Child Processing” is now available for any Manual Import. This can be crucial when importing a native production or preprocessed data in order to ensure attachments which have already been extracted are not extracted a second time during processing.
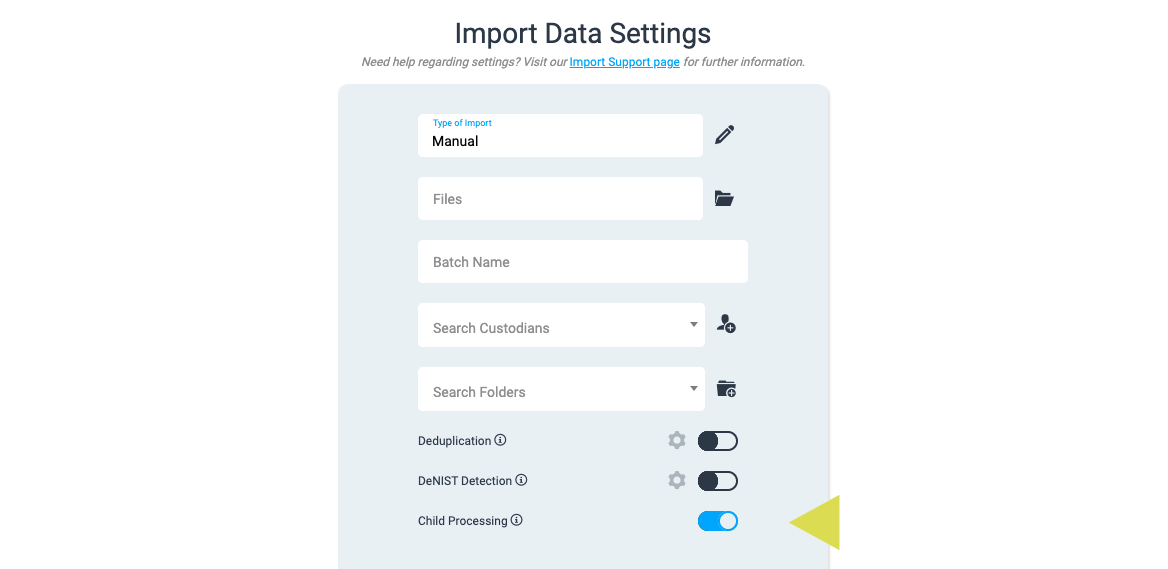
Read more on Disable Child Processing in Step 6 of the Manual Import workflow
Lastly, we made a couple of updates to deduplication logic to ensure context outside of MD5 and Email Message ID is more straightforward. We also removed load file generation for loose file imports in an effort to reduce confusion when importing native client data.
Read more on Import Data Settings and deduplication
Questions? Feedback? Please contact our team at support@nextpoint.com.